Machine Learning Approaches to Question-AnswerinG IS At the Forefront of Natural Language Processing ResearcH. AS such Applications and Models are very recent in the field and are currently being improved upon, My project attempts to Utilize Deep Learning techniques to improve the BIDAF (Bidirectional Attention Flow) model for Question-Answering through Implementing Transformer model elements from the QANET model such as self-attention and positional encoding as well as Convolution Neural Networks to Produce Character-level Embeddings for both queries and Context. Ultimately, my model improves upon the baseline by 4 F1 points and 4 EM points, Exemplifying the importance of contextual and positional awareness and its ability to enhance such Question-Answering tasks.
my full report can be found at this link:
https://www.linkedin.com/in/umar-patel-333788193/overlay/1635486168865/single-media-viewer/
The Following is an Overview of my Research Project

Now leT Us Delve Deeper Into How It Works

Given a Context and a Query, where the answer to the Query is found within the Context, the model will output the Start and End Index Words in the Context which are the answer to the Query. The example above shows the structure of how this works.
Step 1: Positional Encoding

One of the first things I aimed to implement was a positional Encoding Layer that would take all of the Word Embeddings prior to being passed into the BIDAF model and add a positional encoding vector to the word vectors in both the context and the query. The purpose of such a step is that although the pre-trained word vectors contain information about Their meanings individually, they do not possess any positional information on About where they are within a sentence In relation to other words. Thus, by injecting such information into the word embeddings we are conditioning Positional Information along with meaning.
I experimented with 2 Different Positional Encoding schemes: A sinusoidal-Based Positional Vector and a Learned Positional Vector. Ultimately, the Learned Positional Encoding scheme worked better and was the one I Used in my final model.
Sinusoidal Positional Encoding


In the equations above, pos is the current word position in the sequence (i.e., 0 < pos < total sequence length), d_model is the embedding size (100), and i is the current embedding position. I applied the following equations at each word and embedding position and add the resulting matrix to the current word embeddings, essentially injecting the “positional” information into the current word embeddings. I also applied a dropout layer in order to prevent sequences from overfitting to themselves and to ultimately be more robust.
The key intuition stems from two concepts as shown in the sin and cosine graphs Shown Above. First, for different positions in the input, the height of the sine curve will vary with different positions, and so different positions will deviate different amounts along the y-axis, and within a fixed range, providing each position in the sequence a sense of which portion of the input it’s dealing with. It does this without significantly distorting the embedding. Secondly, the issue with the cyclical nature of sinusoidal representations and having later positions in the sequence re-map themselves to values associated with earlier positions is solved through the embedding indices being used to vary frequency of the sinusoidal representations. Positions that are truly close together will retain similar positional embedding values for lower frequencies, whereas positions that are farther apart but that may be mapped to the same sin or cosine value due to the cyclical nature of the curves will differ dramatically as frequency is increased minimally. Therefore, positional embedding encapsulates both these factors to accurately incorporate position information within the embeddings.
Learned Positional Encoding
the Sinusoidal approach to Positional Encoding didn't make any dramatic Improvement to the Baseline Model by itself. Therefore, I developed a learned positional encoding mechanism that would learn a Positional vector which would then be added to the word embeddings, Ultimately picking up on positional relationships that were not identified in the Fixed Sinusoidal Positional vector.
Specifically, I initialized a trainable matrix to be the same dimensions of our input (i.e., sequence length x embedding size) via a linear layer. I then trained this weight on the input by adding the positional weight to the input batch and applying dropout in the same manner as the sinusoidal approach.
Self-Attention
(Ultimately Not Added to final Model)
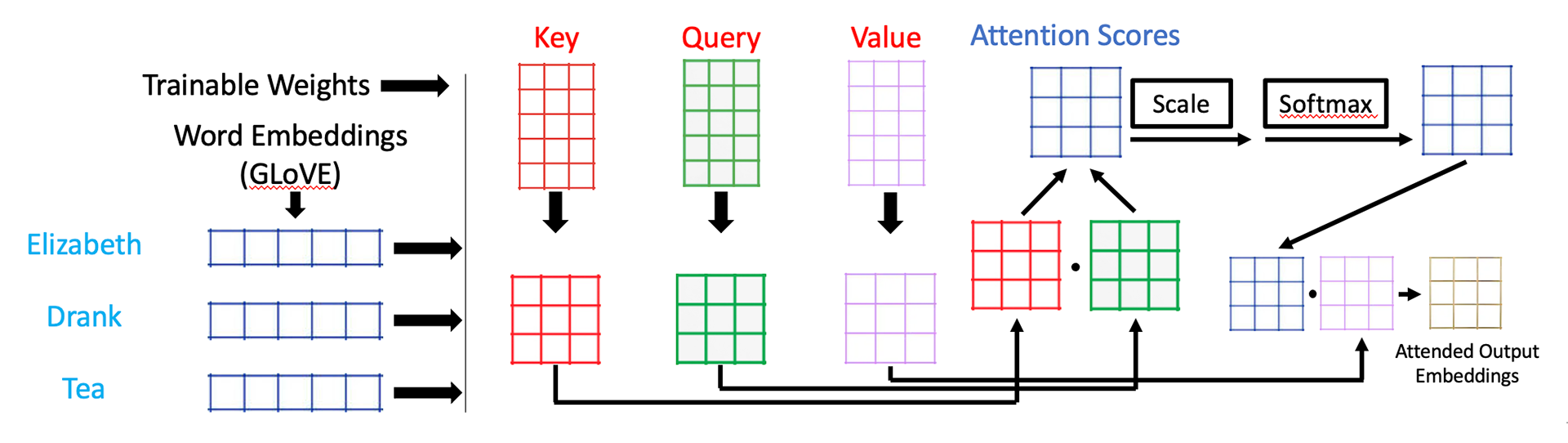
I used the process of Key-Query-Value self-attention to add an additional attention layer prior to the Highway Encoder of the BIDAF model to condition the words in both the query and the context on their surrounding contexts. The process involves inItializing trainable weights Key, Query, and Value, and multiplying all of them with the word embeddings to get 3 distinct Key, query, and Value Matrices. WE THEN MULTIPLY THE KEY AND QUERY MATRICES TO GET OUR ATTENTION SCORES, WHICH WE THEN PASS THROUGH A SCALING AND SOFTMAX layer. Finally, we multiply the resulting matrix with our value matrix to get the fully attended output embeddings, which we then pass on to the rest of the model. As we train, we adjust our Key, Query, And Value embeddings to get optimal attention vectors.
Ultimately, this layer was scrapped from my final model because it actually resulted in worse Performance. I suspect the added Attention Layer coupled with the bidirectional attention flow Layer later on confused the model and resulted in ineffective self-attuned embeddings.
Character-Level Embeddings with Convolution Neural Networks
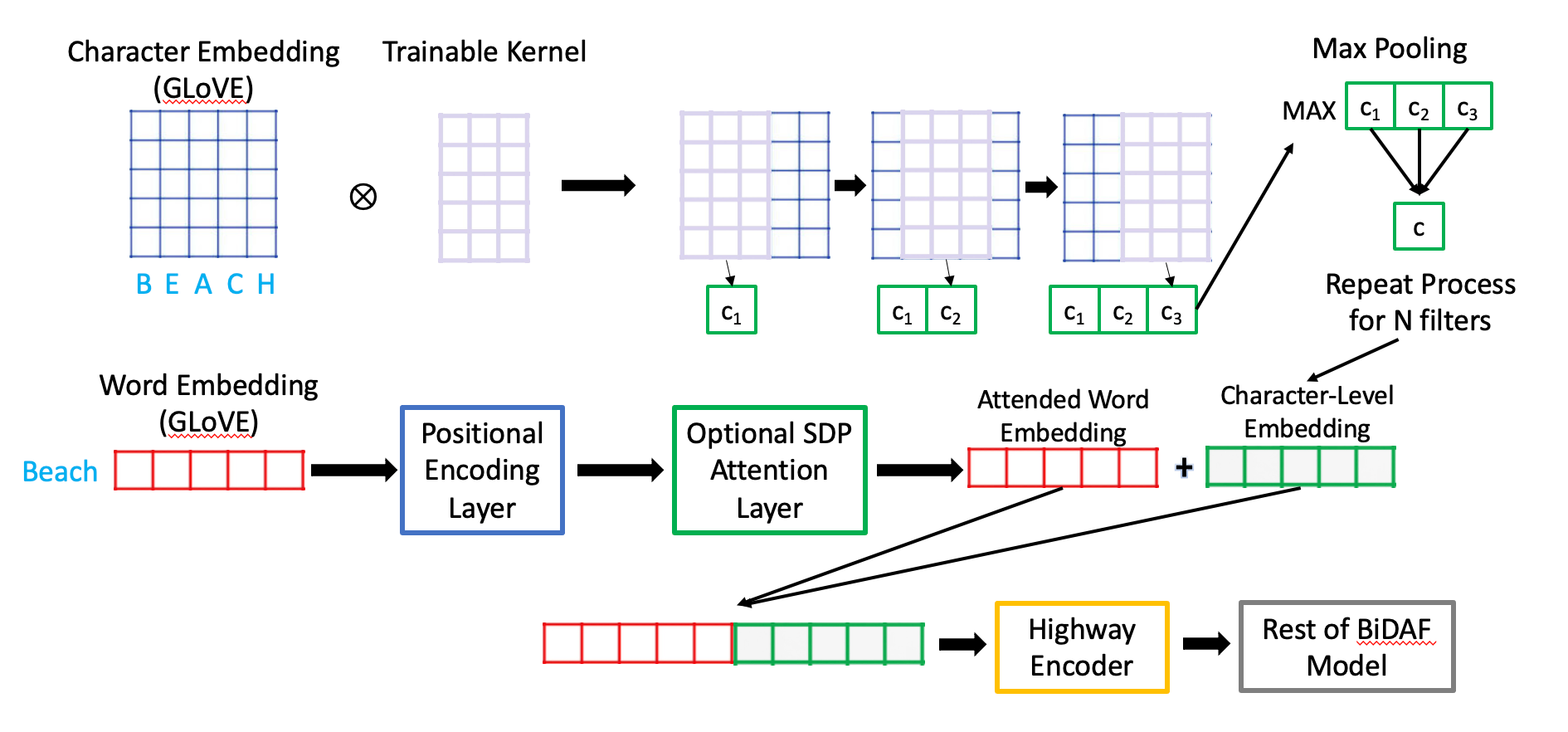
Character-Level Embeddings allow for more specified word representation, as it adds more internal contextual awareness that is not present when simply conditioning attention on the words themselves. Words with similar roots but varying prefixes or suffixes will be treated differently, and this can cause issues in conditioning attention differently on such variations if some are used more often than others. Basically, we want similar words to have similar representations and be treated the same, and do not want words with same roots to be treated so differently because certain prefixes or suffixes make the spellings of the words distinct. To fix this issue, we develop character level embeddings and attach them to each word in order to add internal Contextual Awareness among each of the words.
The specific Approach involves applying convolution Neural Networks with Max Pooling. We use 100 Trainable filters since tHat is the embedding size of the words, and we want the word and character embeddings to be similar in size. I experimented with various width sizes and it seems that convolving over 7 characters is optimal. we then convolve over the word as shown in the diagram above using each filter, and Apply Max-pooling to the result by choosing the highest value as the representative value for that specific filter. We then perform this operation for all N filters (where N is the Word embedding size, in our case 100).
After developing our character embeddings , we concatenate Them with the regular word embeddings, and do this for each word in the query and context before passing them on to the Highway encoder and the rest of the Bidaf model.
EXPERIMENTS
Data

The example to the left is taken from The Official SQUAD 2.0 Dataset.
The output of our model is a start and end Index within the context corresponding to the answer for the given query.
Evaluation
I will use two metrics to evaluate my model’s performance: the Exact Match (EM) score, which is a binary measure of whether the output matches the ground truth answer exactly, and the F1 score, a less strict measure that is the harmonic mean of precision and recall.
Essentially, for the EM score, the model’s answer must match the ground truth answer exactly in order for the score for that example to be 1. If it is not an exact match, then the score for that example is 0.
For the F1 score, we first find the precision of the model’s output answer (whether the answer is a subset of the ground truth answer) and the recall of the model’s output answer (how many words from the ground truth answer did the model output divided by the total number of words in the ground truth answer) and calculate the harmonic mean of the two using the equation (2 • precision • recall) / (precision + recall).
Experimental Details and Results
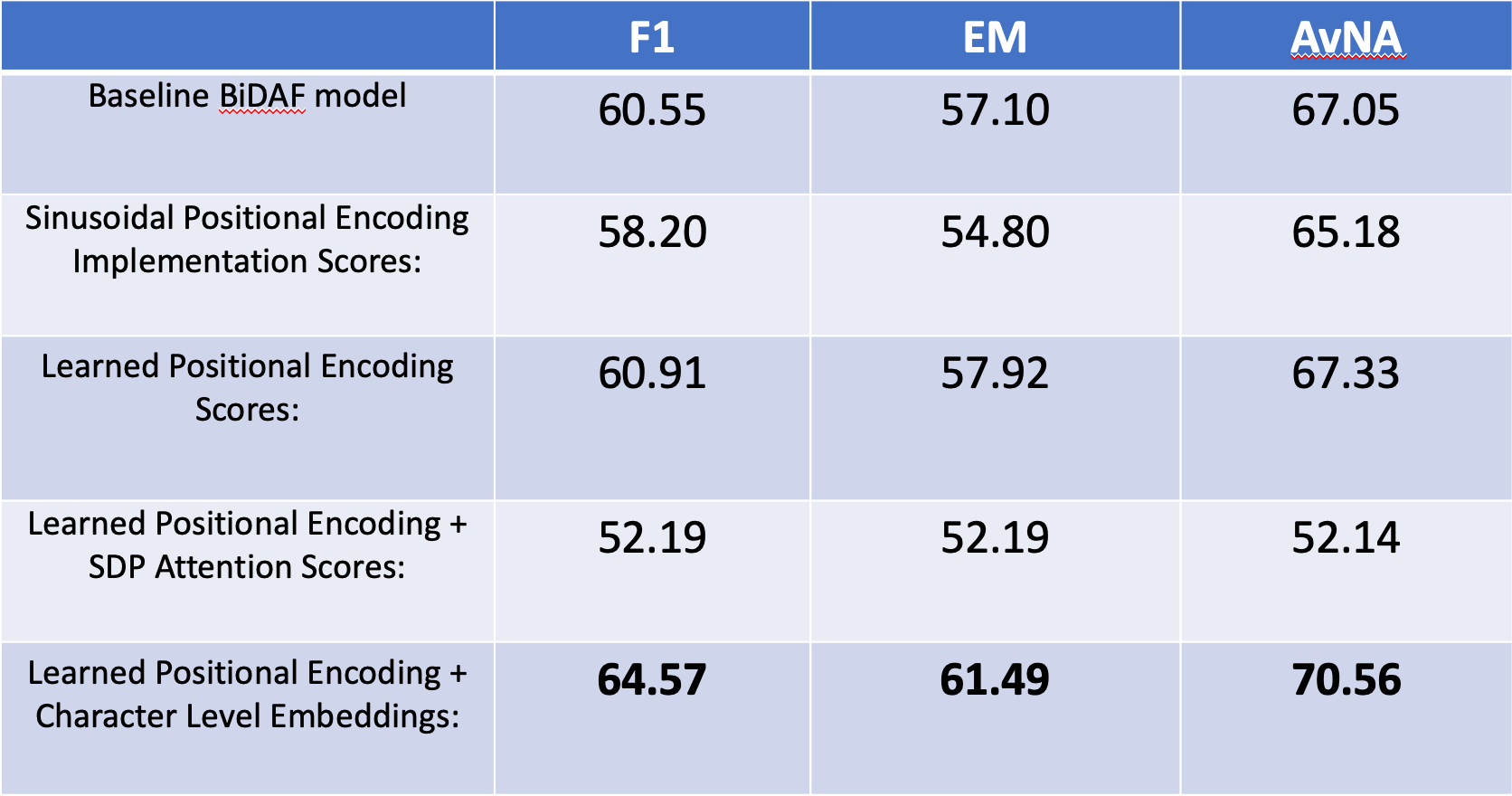
I ran a total of 5 main experiments with different Variations of layers and parameters. For all 5 experiments I trained until completion (30 epochs), which all took approximately 3.5 hours to train.
The first experiment was the baseline BiDaf model. The second experiment involved the implementation of the sinusoidal positional encoding, which actually ended up doing slightly worse than the original. Having seen that the fixed positional encoding method didn't work as intended, I implemented and tested a learned positional encoding scheme which tried to learn a positional information weight, and this ended up working much better. In my fourth experiment, i tested the scale-dot-product attention mechanism along with the learned positional encoding layer and saw that it drastically failed. However, in my fifth experiment after implementing convolution neural networks for added character embeddings, my model performance seemed to improve significantly.
The overall Progress of my F1 and EM scores can be traced in the table above.
here is the F1 and EM score progressions during training.

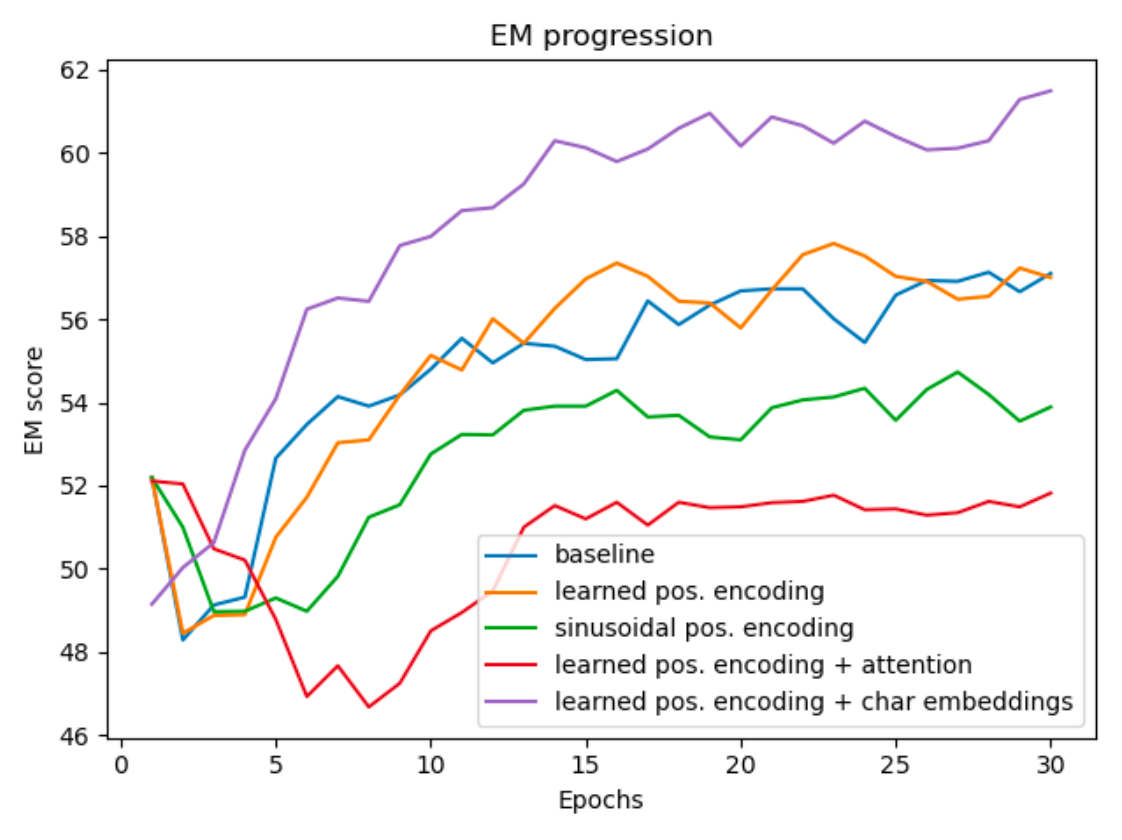
Conclusions and Analysis
I have several hypotheses on why the sinusoidal frequency approach may have worsened the overall performance of the model. It may be because incorporating positional information within a context that is multiple sentences and several hundred words long may start to have diminishing returns when encoding the positional information for words far apart from each other as having little relationship. The contexts are usually about a single general topic and the answer to a specific question (start and end index) may be far away (distance wise) and in a completely different sentence then where the subject of the question might be located. the fixed sinusoidal approach may cause the model to disregard target words that are actually related to the answer of the query but that may be far away from related subject words.
On a more general note, the title of my project was called "Conditioning External and Internal Context Awareness Through Attention Overload and Character-Level Embeddings", but it is clear that Attention Overload isn't as easy and straightforwards as adding multiple attention layers and blocks to a model. I have seen that certain implementations of attention can confuse the model, as was shown in experiment 3. With that said, building up internal and external awareness is essential in improving language modeling tasks since context is such an important aspect of language understanding.
A note from Umar
I avoid simply placing my computer science projects on GitHub. I personally believe that GitHub doesn't do as well of a job as showcasing the process of constructing a computer science project as a portfolio would. Therefore, I aim to display all my personal and internship projects on this site, showing not only my code but also my thought process in constructing the program.