Introduction
Ottoman Turkish is underrepresented in many corpora within Natural Language Processing applications, and with such minimal training data, building robust models for specific NLP tasks on this sparse language has been challenging. My research has revolved around analyzing various NLP and language modeling tools and their efficacy when applied on non-Western languages or older dialects. In the second half of my research project, I leveraged GPT-4 and Semantic Similarity methods to develop several algorithms for parallel text alignment.

Ottoman Turkish is a resource-sparse language which makes it difficult to develop models off of. With a small corpus which is too small for a training set for a particular model, we must explore other ways to analyze such texts.
Potential Applications

Graphic Made by Merve Tekgürler.
The Image to the left shows an early analysis of several documents through topic modeling.
Lemmatization is also a key potential application for Ottoman NLP. Breaking down a word into its components can help reduce dimensionality and enable better morphological analyses.


Doc-to-Doc semantic Comparison would be useful when comparing or contrasting various court histories. The left shows a table Indicating the similarity between several sources we have been working with.
What we realized, however, was that Existing NLP models do not work well with Ottoman Turkish or cannot be configured to work well with the language.
We suspect A major reason why is because of the lack of available training data to build robust models off.
Therefore, we aim to develop novel approaches to perform common NLP tasks (such as machine translation and parallel text alignment) on languages which are not supported via these more traditional means without the aid of large corpora and training data.
using LLMs to provide Semantic meanings and approximate Translations of Ottoman Text
Machine Translation systems are typically created by explicitly defining translation rules and having a large amount of training data. However, LLMs have the potential to generate translations without relying on parallel corpora.
Furthermore, we find that LLMs are better at approximating translations for Ottoman Turkish as it does not rely on specific sequence-to-sequence and attention modeling that most NMT approaches use. These work best when embeddings for most words are available, which is often not the case for Ottoman Turkish, where many words could be unrecognizable to the model.

Left (MT Seq2Seq Model): Sobh, Ibrahim. “Anatomy of Sequence-to-Sequence for Machine Translation (Simple RNN, Gru, LSTM) [Code Included].” LinkedIn, 25 Mar. 2020.
Right (LLM-based GPT model): Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
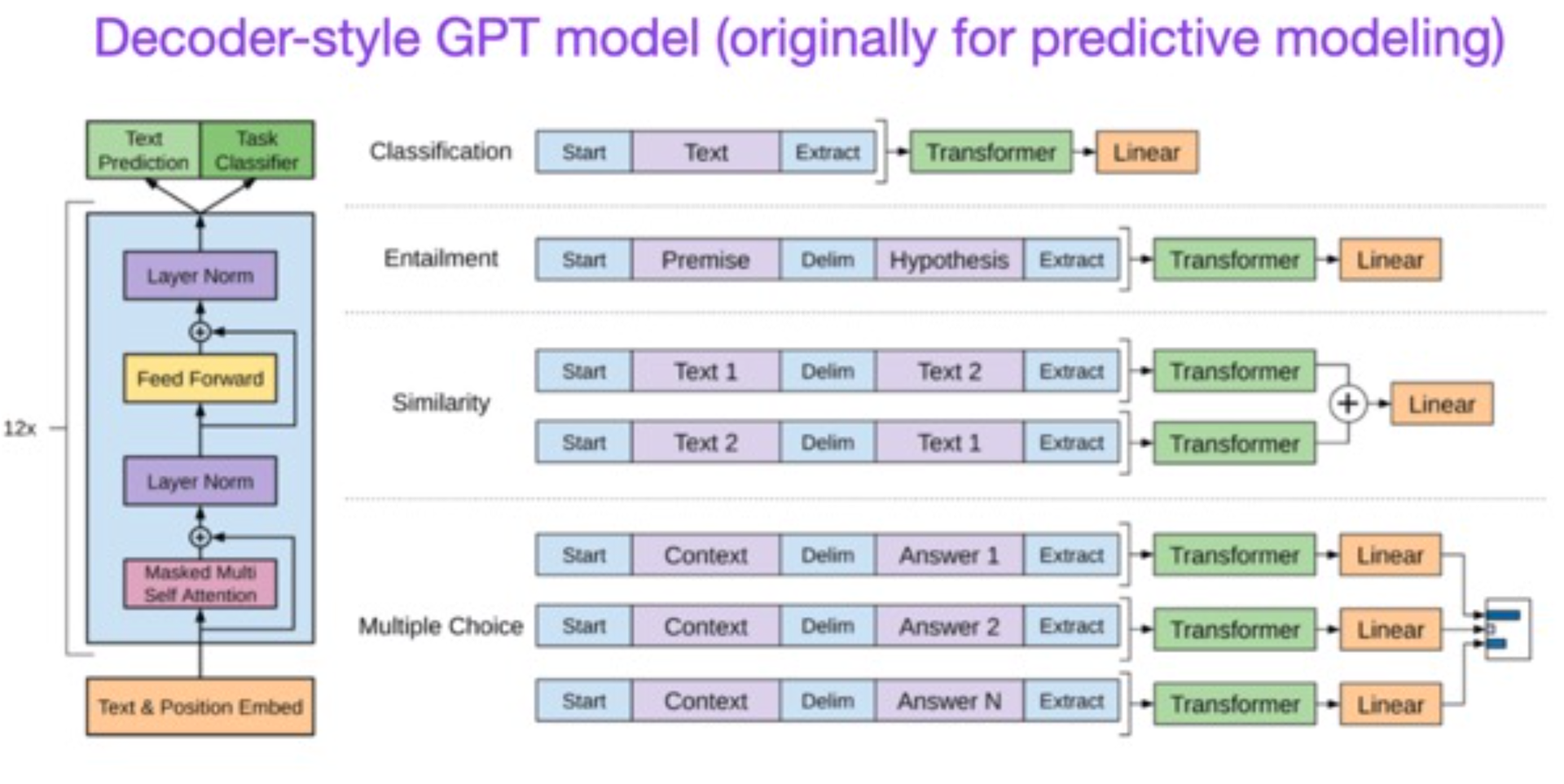
Large language models are trained to predict the next word in a sentence and have the capability of generating text, whereas MT systems are largely trained on pairs of texts to translate from one language to another.
LLMs provide us with a means to generate translation without using sequence-to-sequence encoding and decoding that is optimal only when large corpora and corresponding translations are available. They also allow us to perform highly specialized tasks (such as parallel text alignment) on data- sparse languages that would be difficult for other NLP models that do not leverage the generative capabilities of LLMS.
Ultimately, while LLMs may not provide exact word-for-word translations for Ottoman Text, they do provide outputs whose semantic meaning is similar to the original text, and so this can be used as an approximation for a model "translation"
When comparing the gpt-translated segments to the ground truth segments they are supposed to align to, we get the following measures (over the first 20 segments)

Notice that while the Bleu score, which is a more direct measure of word-to-word translation, is low, the cosine similarity between the GPT-translated segment and the Ground truth is quite high. This shows that while the LLM- generated translation may not be that accurate on a word-to-word scale, it does still pick up on the overall meaning of the segment quite well.
Therefore, we could use the GPT-translations of each of the segments, as well as the known Ground truth sentences for the work, to conduct Parallel Text Alignment: the process of aligning each segment of the original text (in Ottoman Turkish), to its corresponding sentences in the ground truth.
Next, We Show some promising approaches to conduct parallel text alignment.
Formal Approaches
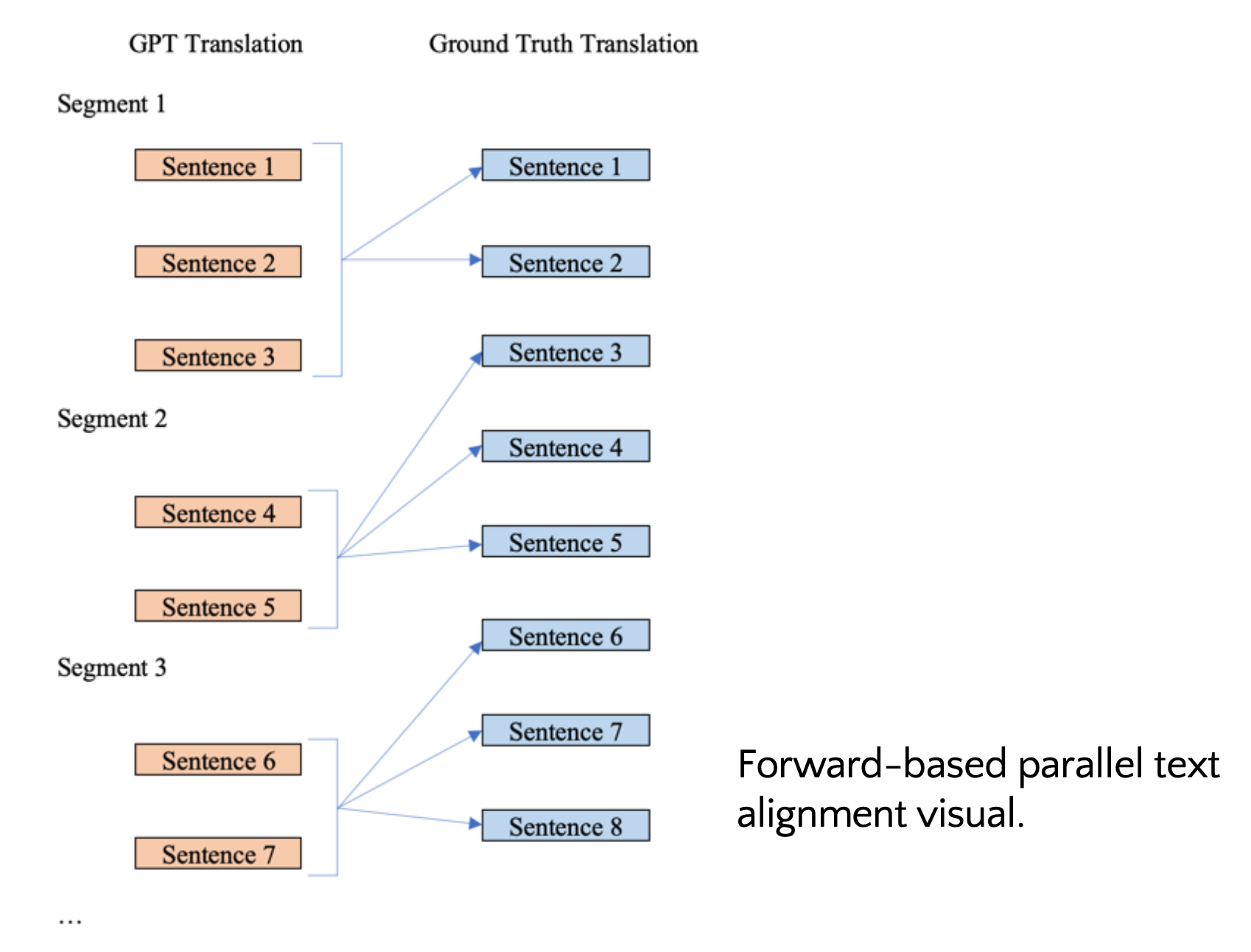
You can iterate over each segment in the GPT-translated text (which could contain one or more sentences as shown on the left) and then prompt GPT to select the n next sentences in the ground truth that correspond to the current segment.
Alternatively, you can set up a buffer of size n representing the next n sentences in the ground truth. Then, you start with the first sentence in the buffer, iteratively adding one more ground truth sentence, each time computing the cosine similarity between the current sequence of ground truth sentences and the gpt-translated segment. You would expect the cosine similarity to be highest when you have just the right number of sentences in the ground truth sentences buffer to map the current gpt-translated segment, dropping off with fewer or more sentences from the buffer.
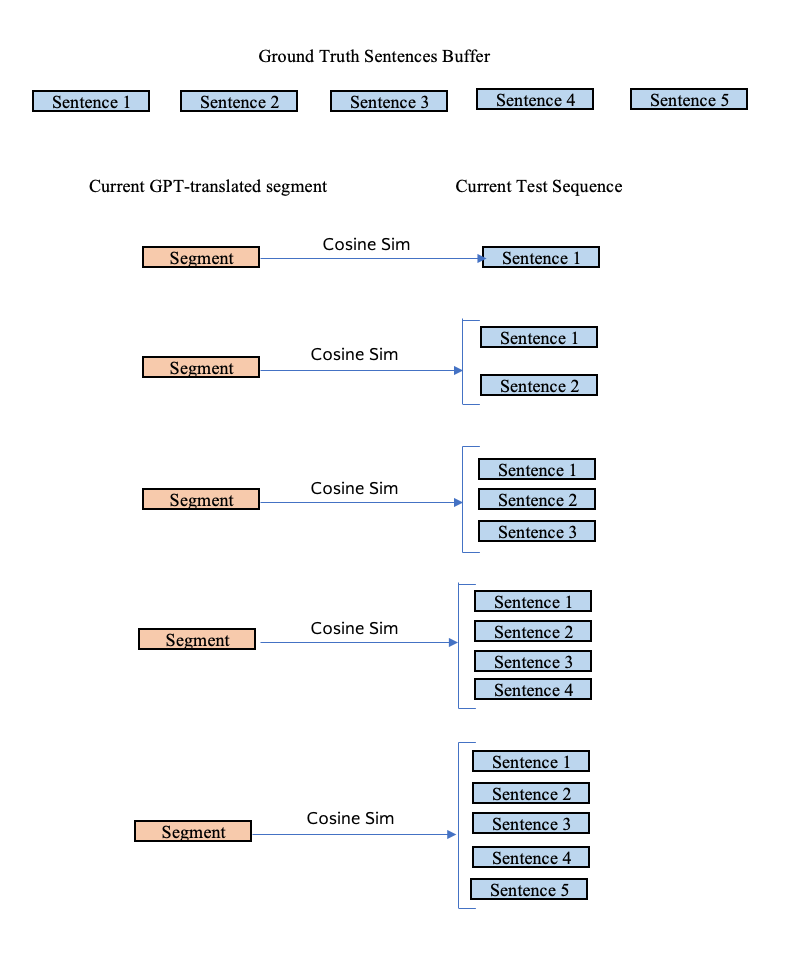
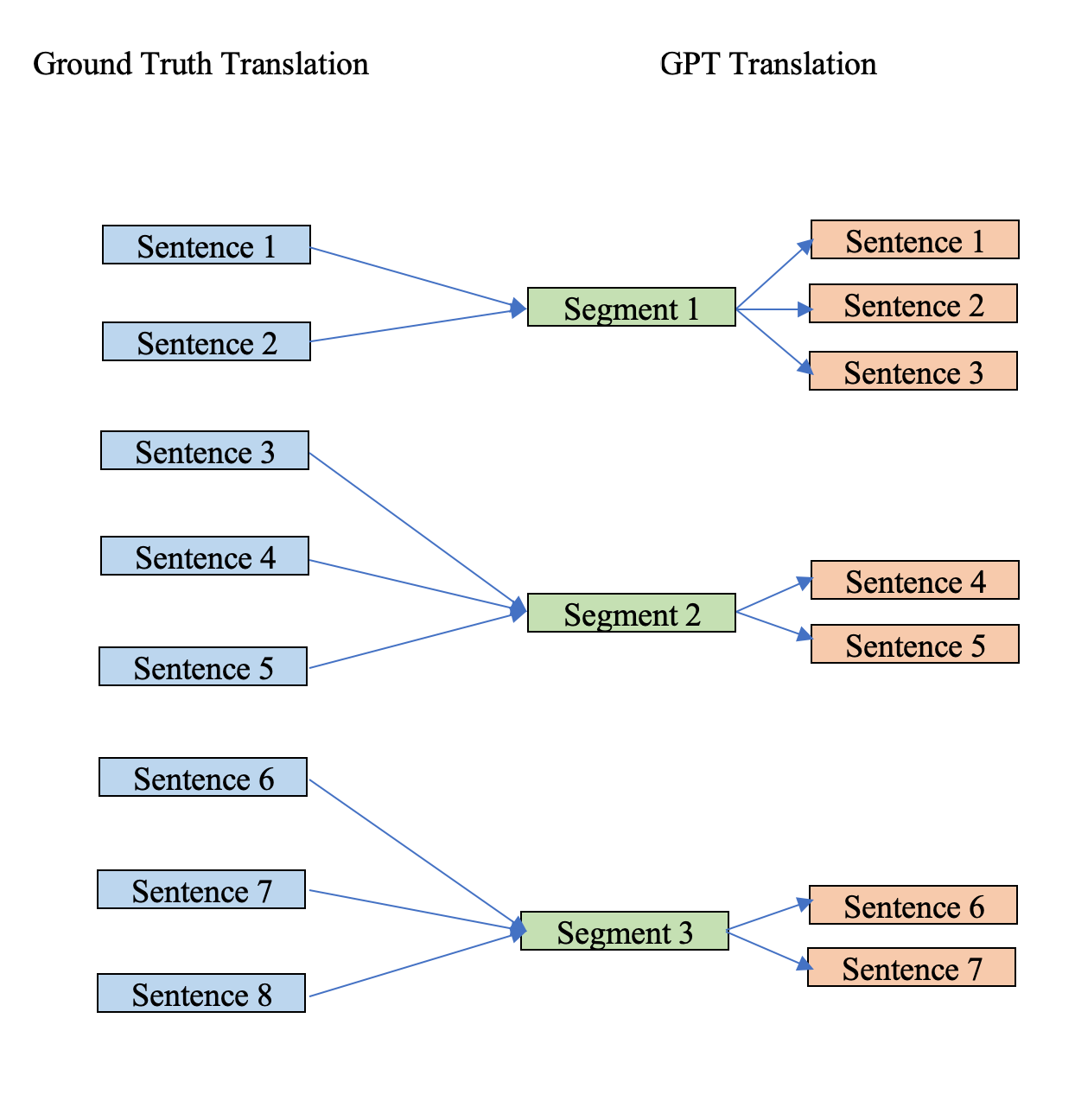
Another promising approach is to try reverse aligning the text. That is, Iterating over the ground Truth Sentences and assigning them to the corresponding Gpt-translated segment.
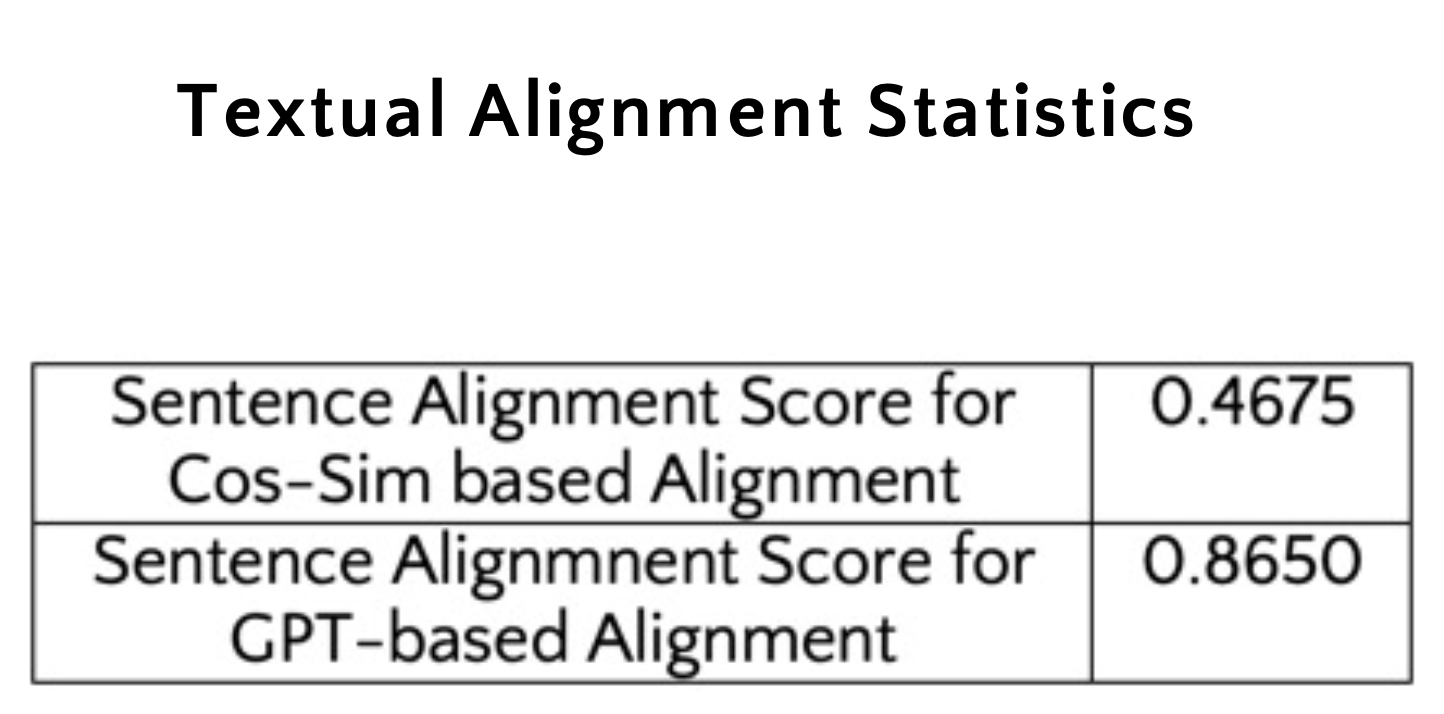
the following results shows the efficacy of the first two approaches outline above:
Clearly, the GPT-based parallel text alignment approach works best, with a sentence alignment score of almost double that for the cos-sim based alignment.
Understanding the scoring for parallel text alignment
Sentence Accuracy Metric:
- Since our scheme for both aligning the translations (in both the cosine similarity and gpt-4 prompting approaches) are based on adding the ground truth sentences to the respective segments, we will use a sentence-based score which is calculated as follows:
- The total score starts off as the total number of sentences in the ground truth for the respective segment.
- For every sentence missing in the aligned text, we subtract 1 from the total score.
- For every additional sentence that is added to the aligned text that is not in the
ground truth, we subtract 1 from the total score.
- The final sentence-based score for the segment is the final score divided by the
total number of sentences in the ground truth.
- Minimum score per-segment is 0. Maximum score is 1.
Next Steps
- Test a combined GPT prompt-based and Cos-sim approach to parallel text alignment, where you can use cos-sim as a first pass alignment scheme, and then prompt GPT to correct the alignment by shifting the current matches to the corrected ones.
- If the project receives more funding through our OpenAI grant, then the resulting data from the parallel text alignment could act as training data for a mT system, and we could train a model as such (although this model would be heavily biased toward the Ottoman court histories upon which the training data is based off of).