Project Setup
For this project, I am focusing on training a model on the dataset’s images to construct a reasonably functionable genre and era classifier. While the dataset’s labels include categories like artist, style, and brushstroke, we will focus only on genre and dating.
When it comes to the date/era of each painting, while the dataset provides the exact year that the painting was created, our model will focus on classifying a span or an era, since having a model predict the exact year would not be a reasonable metric.
With this in mind, I am trying to answer whether or not we can construct a baseline model using CNNs that could classify historic paintings by genre and era. I am also interested in exploring how to set up the best framework in terms of image processing and model network to allow for not only accuracy, but efficient training and testing
Dataset
Kaggle, Painter By Numbers Dataset
Classifies over 40GB of Painting Images over the last millenia by Genre, Style, and Era, among other categorizations.


Model Architectures
Experiment 1

I start with 2 convolutional layers, each followed by max pooling layers to extract features from the images.
After flattening the 2D matrices into a 1D vector, we have a fully connected layer with 100 units and ReLU activation, followed by a dropout layer to prevent overfitting.
The final dense layer uses a softmax activation to output the probabilities for each class.
First Model Architecture and Approach Review
After constructing and training this model, I realized that one of the main issues was that there were too many classes, and specifically, most classes had very few images associated with them during training. While a few top-heavy genres or date ranges in terms of training, most classes were not adequately being trained on. Therefore, it would make sense for this analysis to condense the number of classes. Furthermore, I realized that I could also make training more efficient by further reducing the input image size and increase the batch size. To test this, the following is my new model architecture
Experiment 2 (reduced Classes)

Simplified Model with a reduced Input Size.
Training
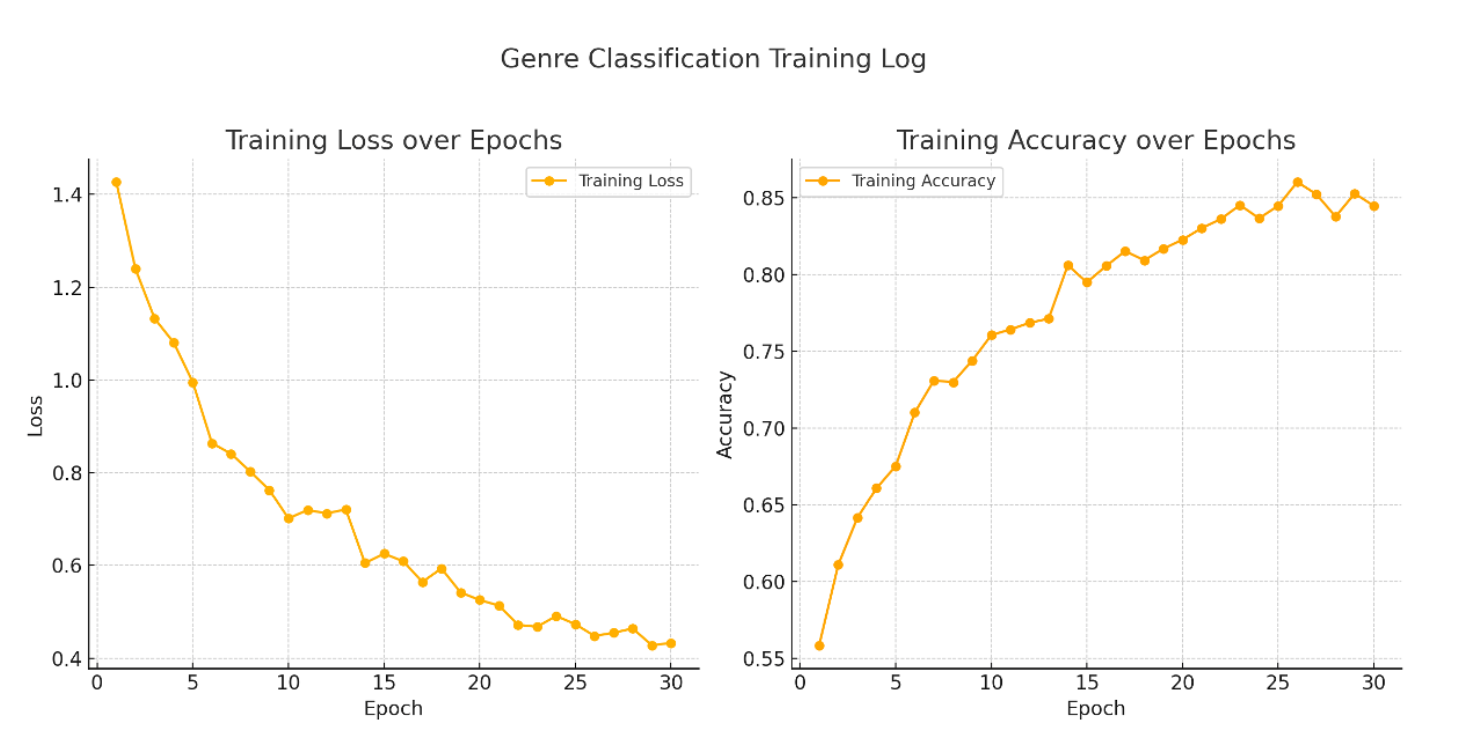
Genre Classification Training Log prior to Reducing Classes
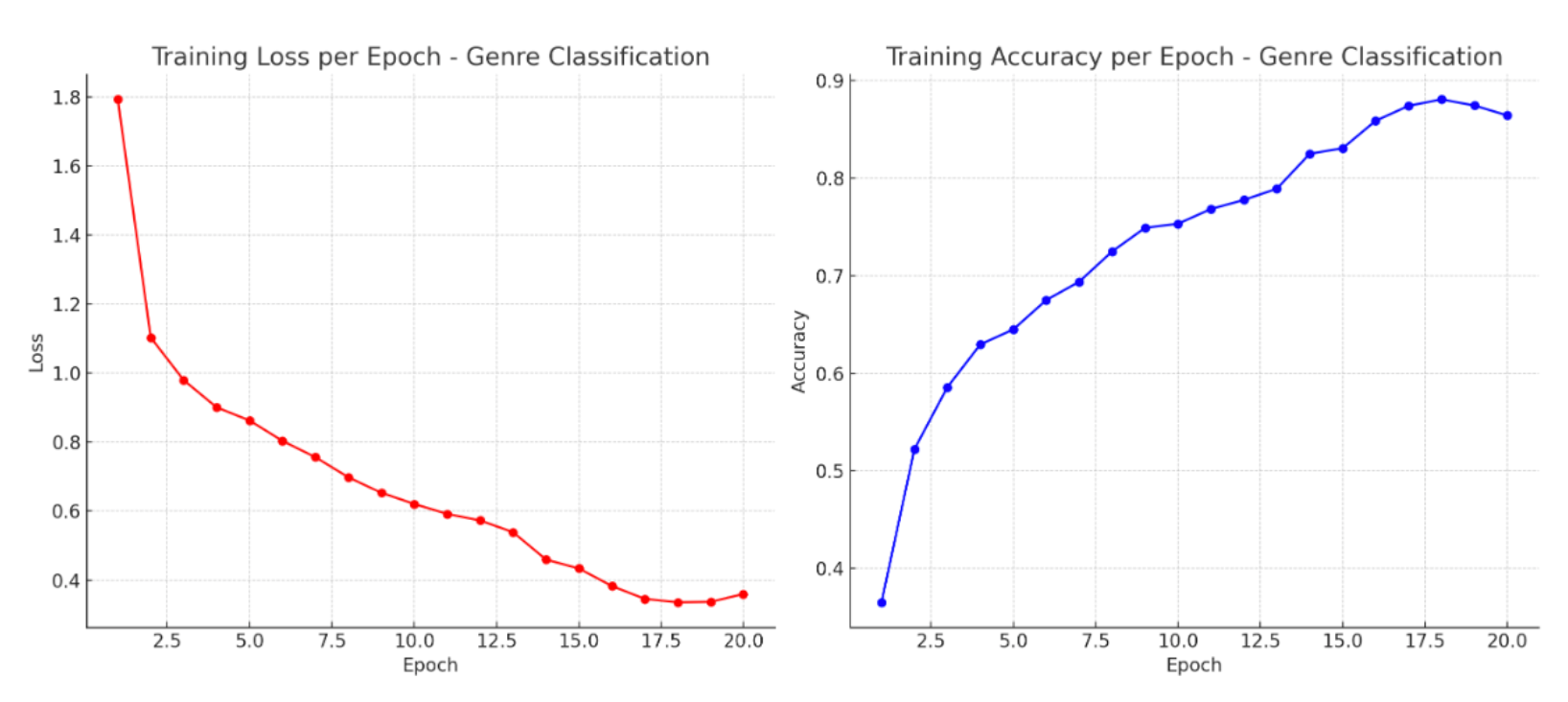
Genre Classification Training Log After Reducing Classes
REsults and Evaluation
Genre Classification – 39 Classes: 0.2750
Era Classification – 14 classes: 0.3516
Genre Classification (Classes condensed) – 4 classes: Portrait, Landscape, Genre Painting, Abstract:
0.6036
0.6036
As you can see, as the number of classes decrease, the accuracy of the predictions also increase.
GPT-4 Experimentation
One final Experiment I Conducted was ask GPT-4 to analyze some of the images and see how accurate it was at classifying the genre of each. Here are the results of 8 random samples from the dataset.
39986.jpg: Abstract (Correct)
23235.jpg: Landscape (Incorrect, categorized as Abstract)
30650.jpg: Genre Painting (Correct)
30259.jpg: Portrait (Incorrect, categorized as Genre Painting)
31118.jpg: Abstract (Correct)
100390.jpg: Portrait (Correct)
36698.jpg: Genre Painting (Correct)
2051.jpg: Landscape (Correct)
COnclusion
GPT accurately predicted 6/8 correctly, which is a 75% improvement over our model’s 60% (although it was a very small sample size, so that must be taken into account). Considering our training limitations, I’d say our model performed fairly well. The errors it did make were in confusing genre paintings with portraits and confusing a landscape painting with an abstract painting. I suspect even in our model that these would be the most likely mis-predictions. Many genre paintings contain people, and so the model could pick up on that feature and classify the work as a portrait. Additionally, older landscape paintings seem to have rough textures and minimalistic details which could confuse models to interpret them as abstract works of art.