Information retrieval is a machine learning and natural language processing technique which essentially takes some form of a user query and retrieves the document which has the highest similarity to the query. This ML technique is used primarily in search engines such as Google, but it can also be used to search for relevant information in large databases.
Overview
Of course, I do not have access to all of the different websites on Google. So For this project, I wanted to construct an information retrieval search engine for approximately 40 websites, each of which represents one of the monarchs of England from the Norman conquest in 1066 to present day. Basically, the program would take in any query regarding British History by the user and return the top N websites that the user can look at to Acquire more information about the topic.
Basically, you can Think of this as Google but for the last 1000 years of history in the British Isles.
Step 1: Acquiring the Documents

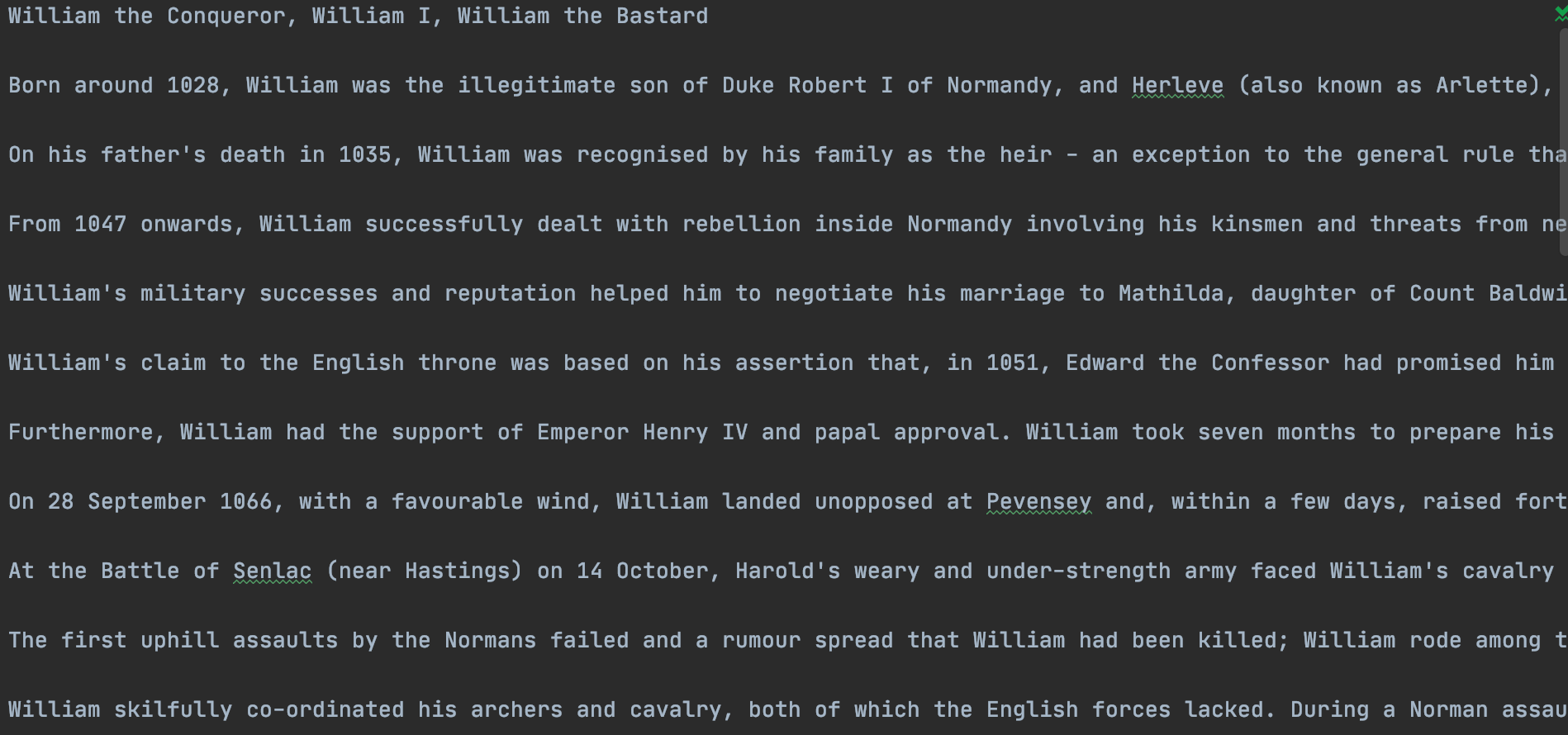
I took about 40 web pages off of royal.uk, each of which is about a monarch of England, converted them into text files as shown below. Notice that if a specific monarch has more than 1 historically associated name, then it will appear as a comma separated list in the first line of the text file.
Step 1: Setup
Key Libraries we will use in implementation
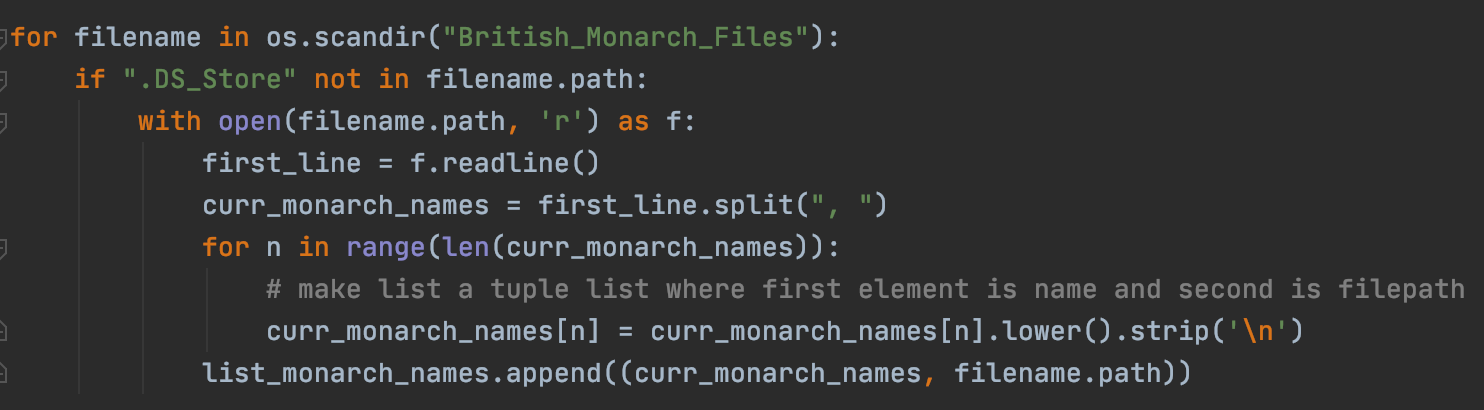
Extract all the names for each of the monarchs and store them in a list. If a query is found to have one of these names, it will direct the user to said web page.
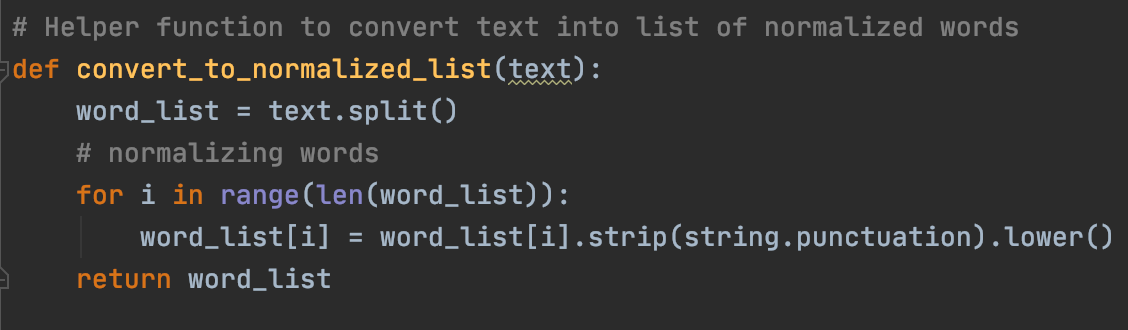
This function takes in a string form of text and converts it into a list of words removing any punctuation as well as normalizing the words so that they are all lowercase.
Step 2: Building Positional Index and TF-IDF Data Structures
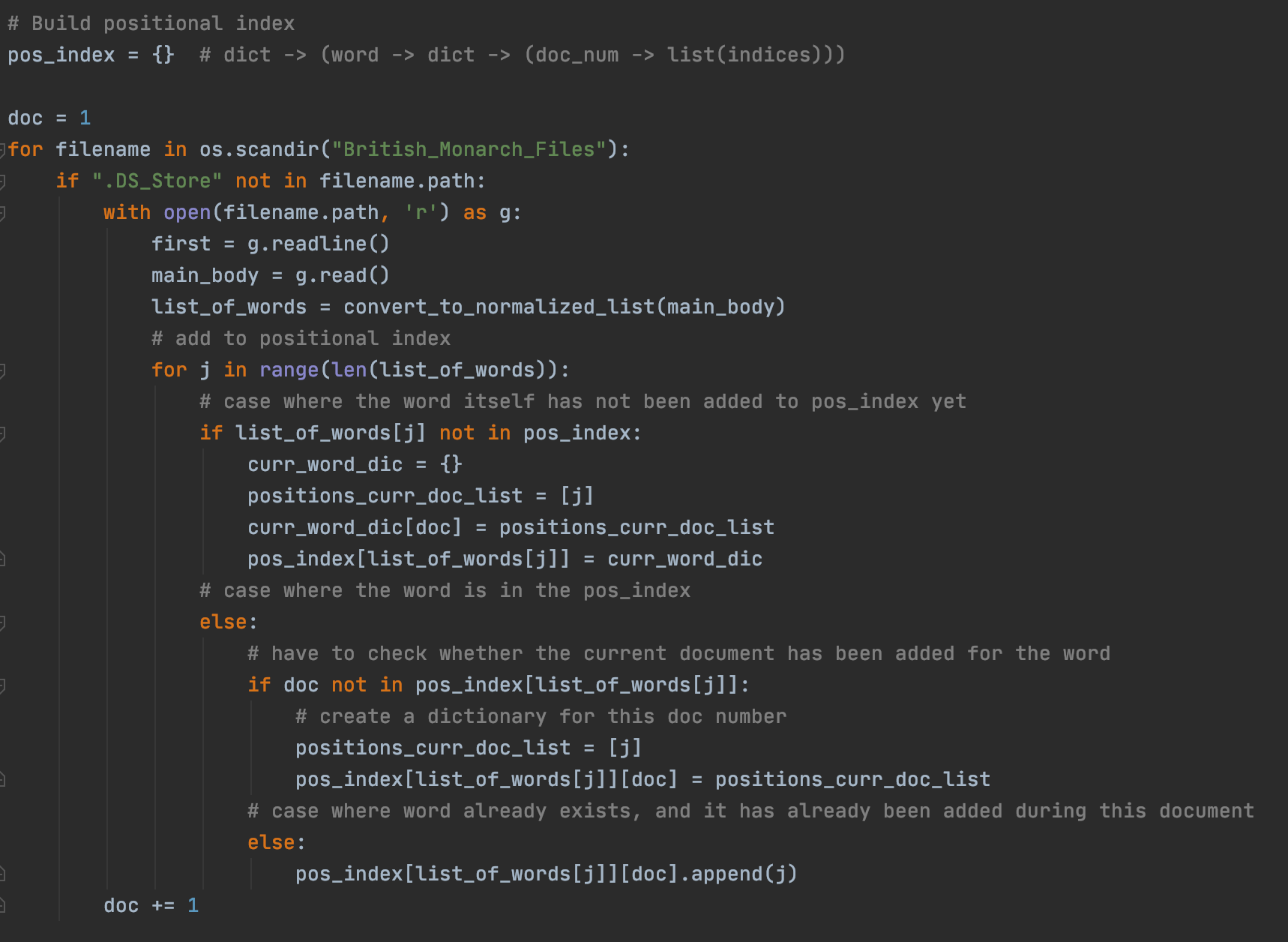
a positional index is a data structure which maps each keyword to a dictionary containing the documents (or web pages) which the word can be found in as well the indices of the appearance of the word in each document. the following snippet builds this positional index for all the words that appear in the monarch documents.
This dictionary will be important for us when implementing the positional index method for information retrieval.
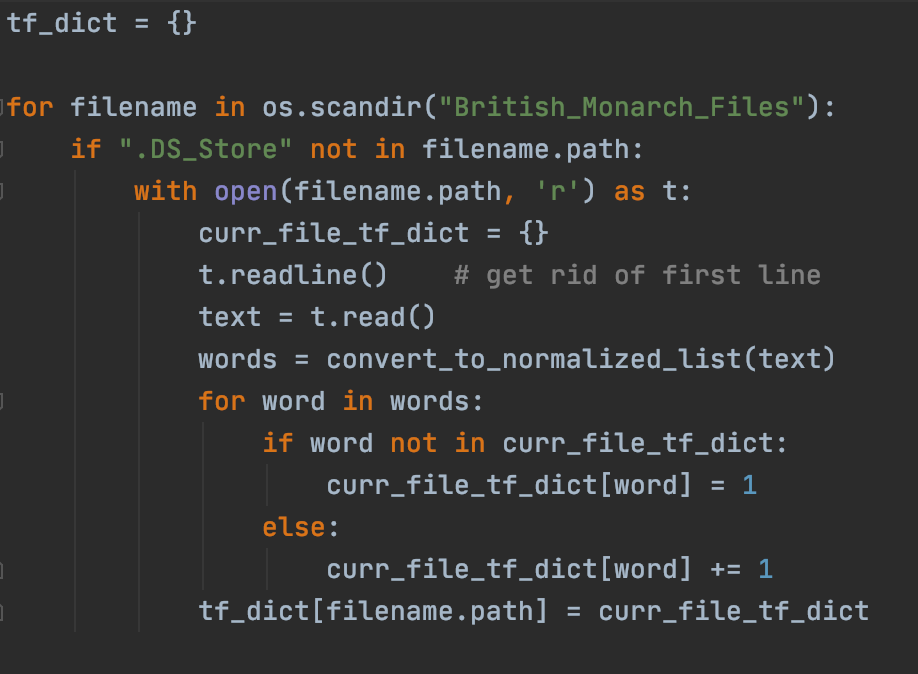
A Term frequency dictionary is used in the Tf-Idf frequency algorithm which stores each of the words in each web page as well as the number of times that word occurs. In the snippet below, we go through all the files and then add the terms-frequency dictionary to tf_dict.
Step 3: Main Functions
Positional Index Approach:
This function checks to see if the query contains any of the monarch names or alternative names listed in the first line of each file. If it does, then it will automatically return that document as one of the options. in many cases in information retrieval, the main topic of an article may not always be contained within the article. This ensures that if the user searches for the main topic, the document that corresponds to that main topic will always be retrieved.

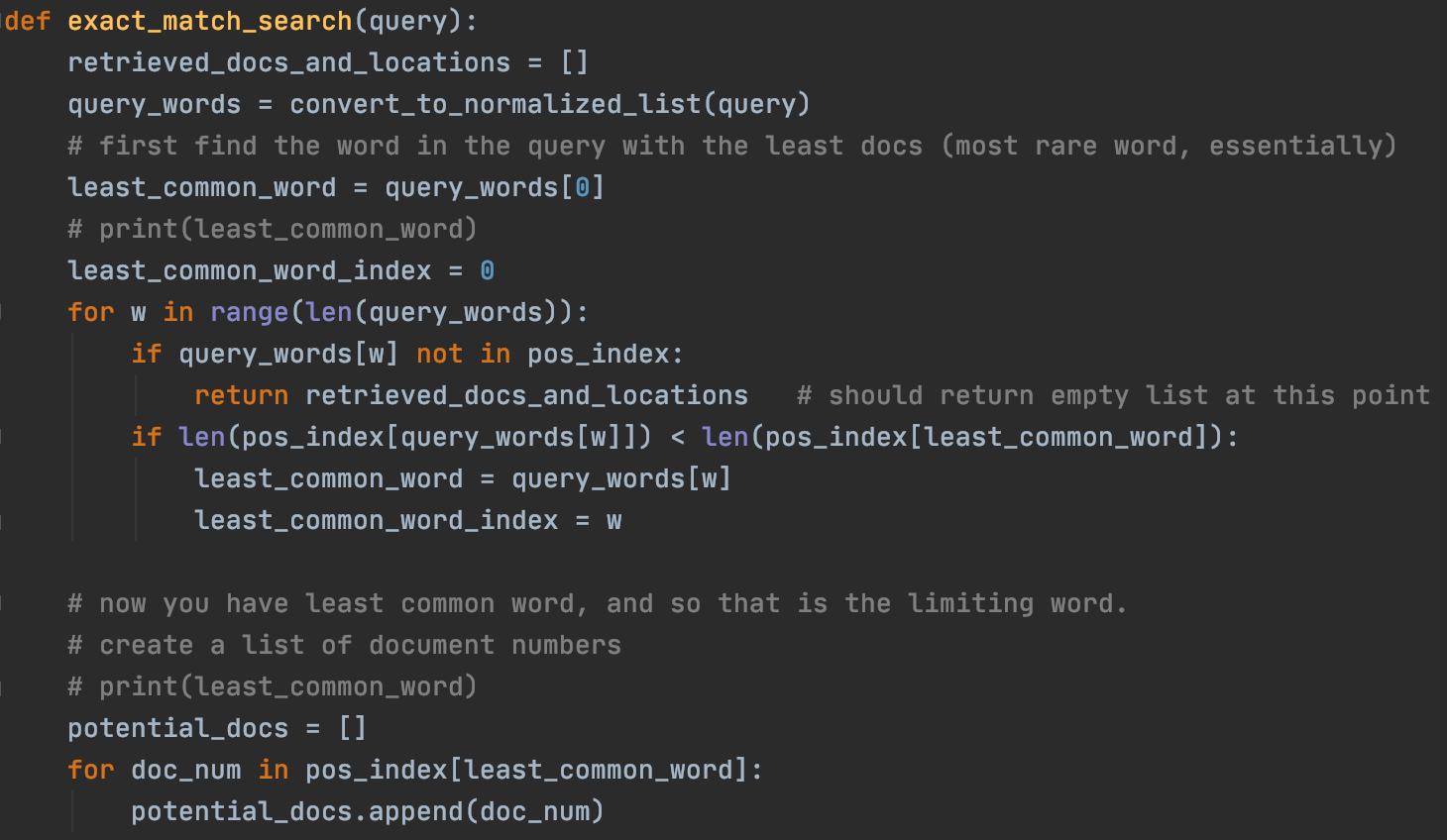
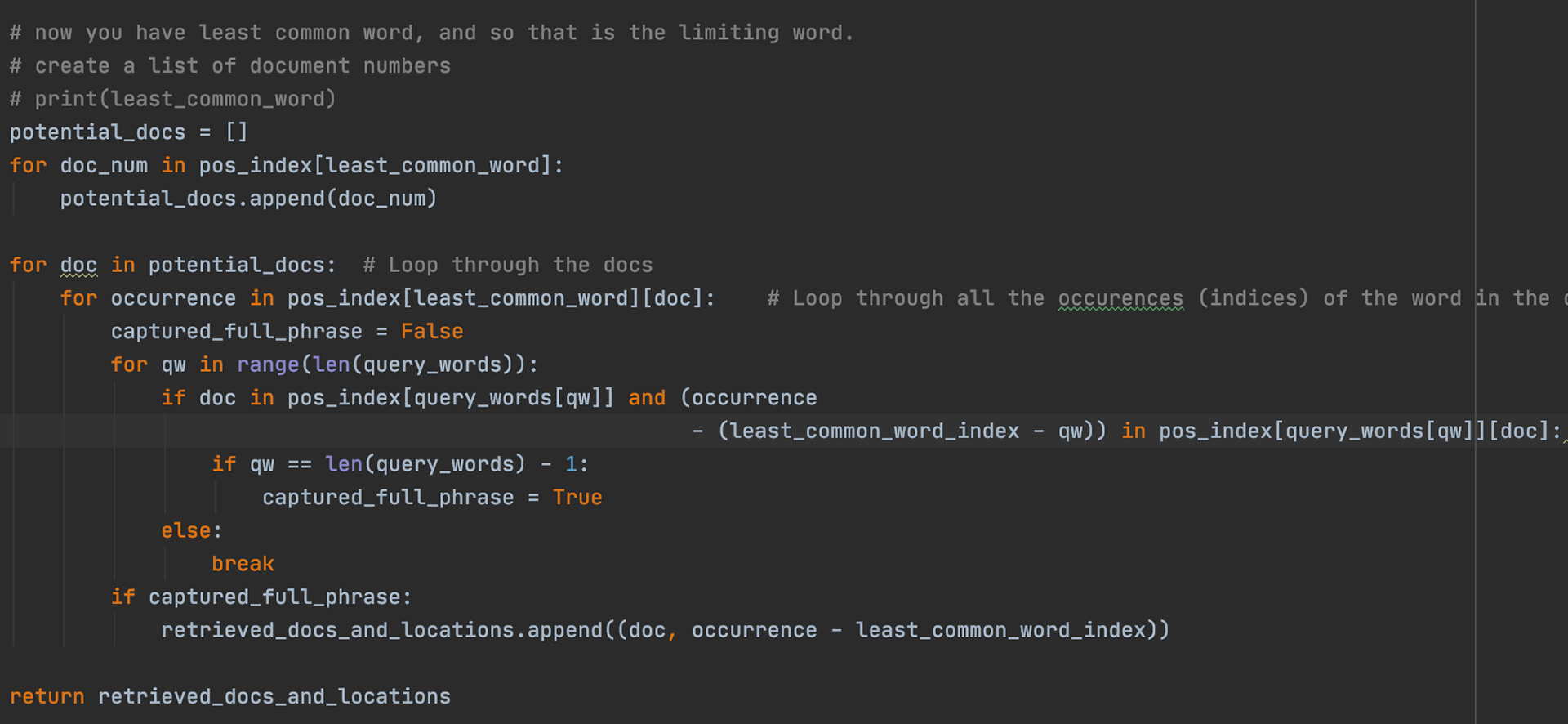
The function exact_match_search takes in a query and then checks to see any of the documents contains an exact match. It does this by using the positional index data structure. Essentially, it will search the positional index for the first word in the query, check the documents in which it is contained as well as the positions, and then go on to the second word in the query, repeating this process for all the words in the query. The key insight is that in order for their to be an exact match, you must find all the query words in the positional index as well as find them in successive positions in the positional index.
Tf-IDF approach:
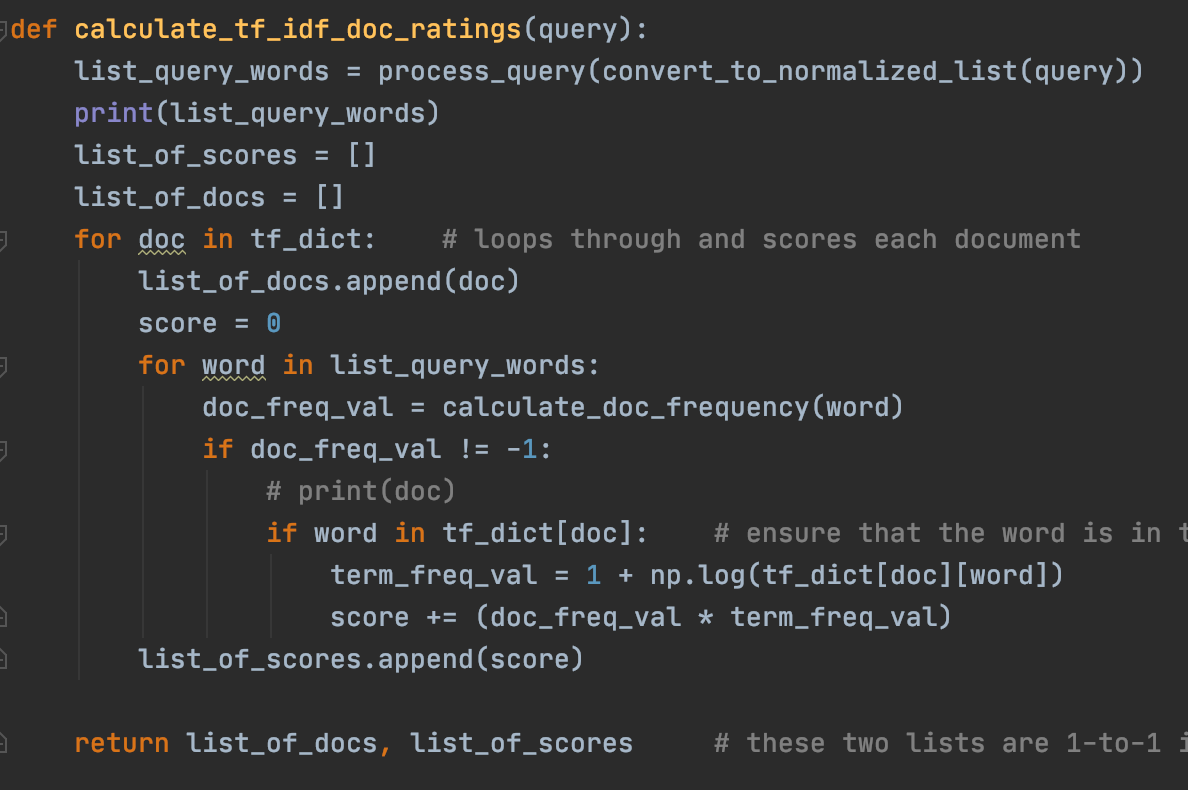
The function Exact_match Search works well when searching for an exact match. but sometimes an exact match between a query and a document is not found, but that doesn't mean there isn't any relevant document to retrieve. In these cases, we must treat every word in the query individually and try to match the document(s) with the highest tf-idf (term frequency - Inverted Document Frequency) value.


The first step in the tf-idf approach is developing some helper functions that will allow us to extract all the information we need about the words in the query.
Process query extracts all the non-stopwords that are in the query since stopwords do not tell us anything about the content of what the user is trying to look for.
Calculate_doc_frequency is a method that takes in a word and calculates the inverse document frequency for that word among all the documents. Notice that we return the value N / num_docs_with_word. This is because Query words that are only in a few documents should be weighted more than words that are in all or most of the documents. They are better at distinguishing among the documents. Also note how we apply the log function on the quantity to dampen the effect of idf.
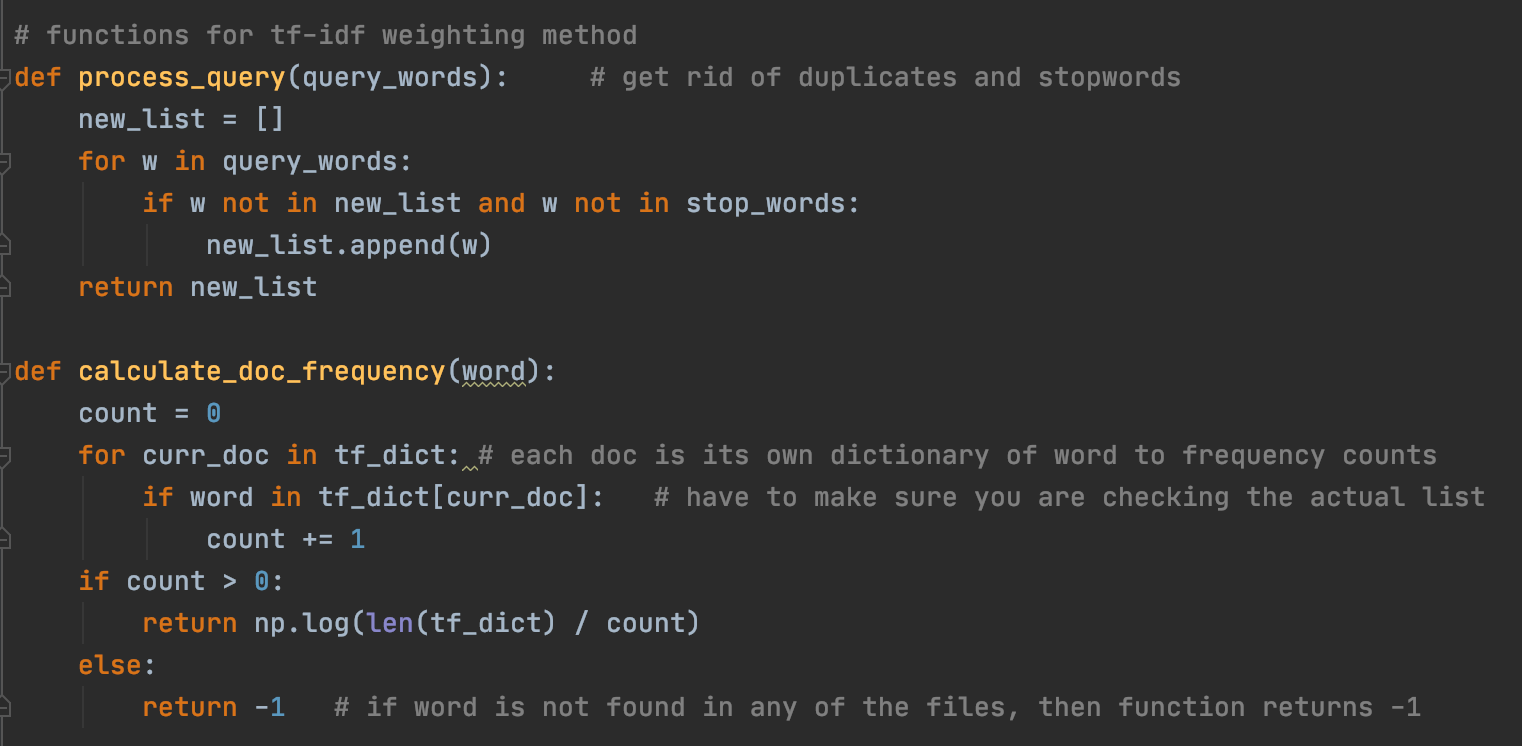
The term frequency is basically the number of occurrences of a term within a specified document. for the specific value we use in the tf-idf calculation, we use the quantity 1 + log(term frequency) to account for the the instance when term frequency is 1 and log(term frequency) is 0. This function also calls the calculate_doc_frequency function described above to acquire the document frequency of the word, and conducts the overall tf-idf calculation.
Step 4: Organized Output
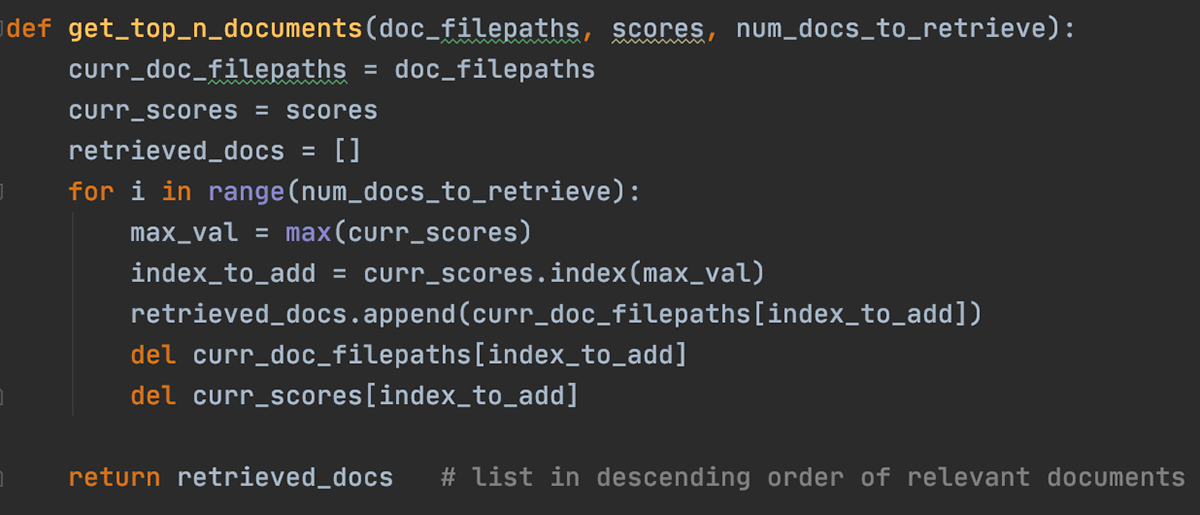
This helper function takes in some of the lists and data structures that we constructed above and returns the top n documents (or web pages).
There are two retrieval methods that we built up in this project: the positional index method and the tf-idf frequency method. in our interface, we will give the user the choice of which one to use so we can see the differences and similarities between the two!

Some finishing touches to make the output appear neat and clean.
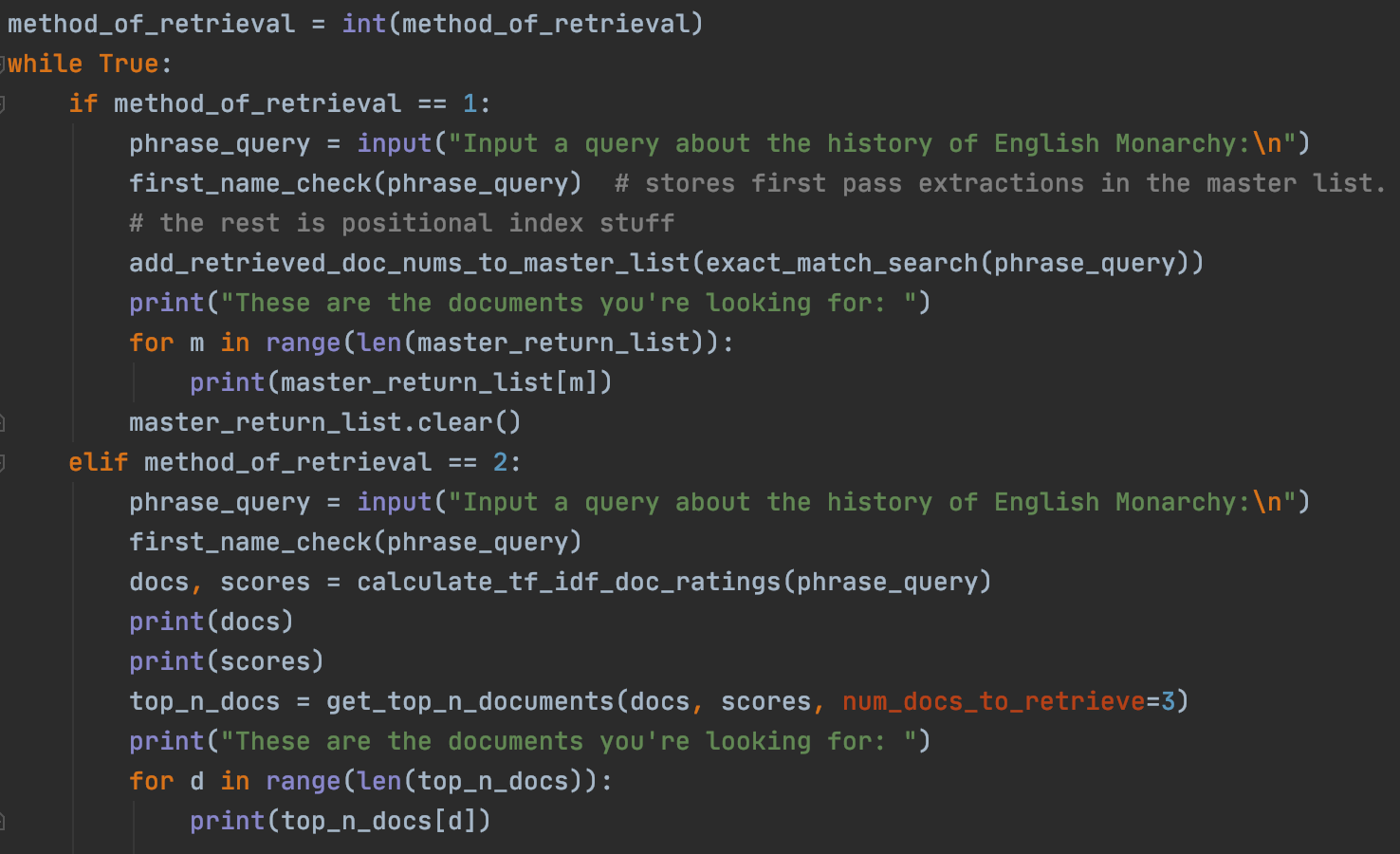
Output and Results
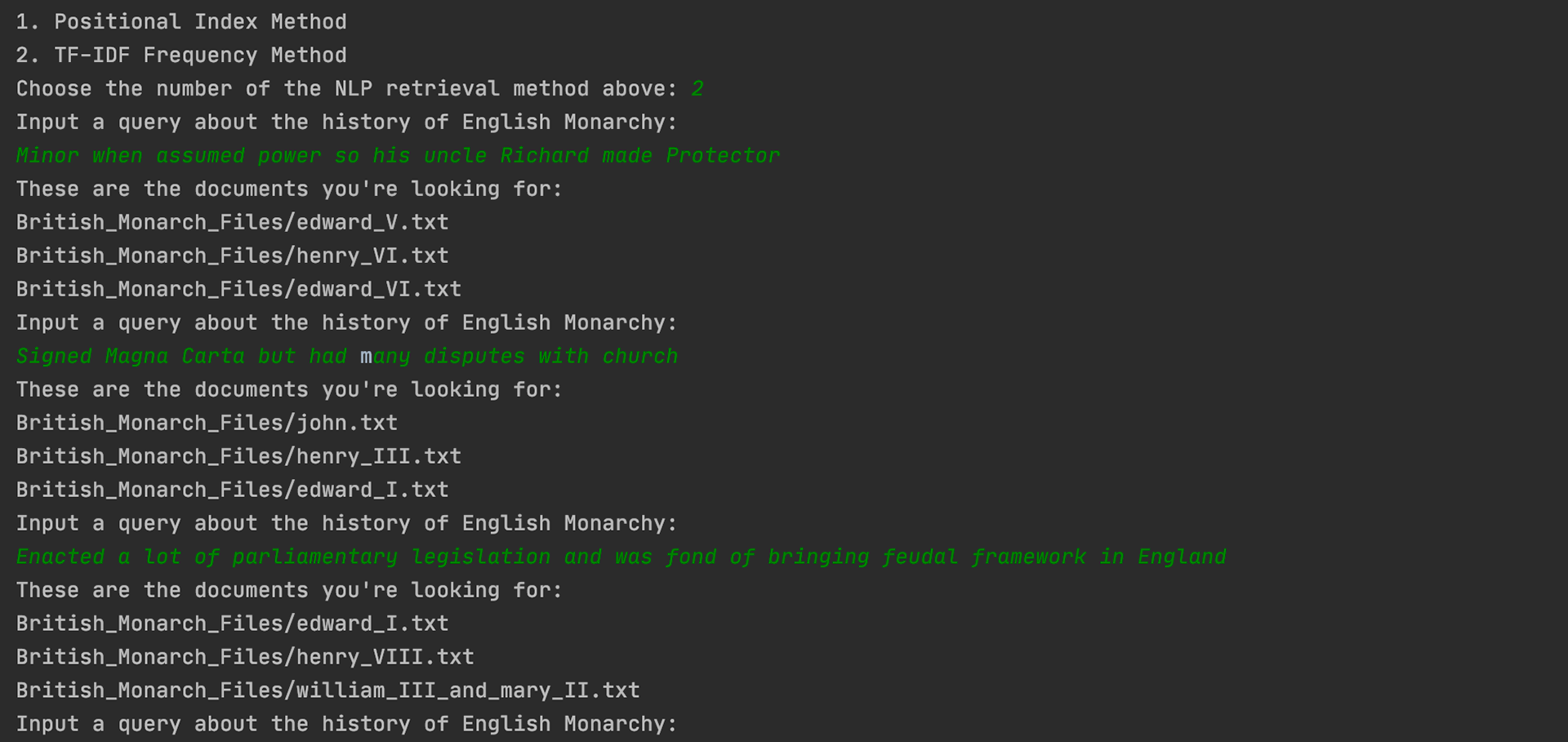
If you are doubtful of the results, you can do some research to confirm that the top monarch pages that are retrieved do indeed correlate to the query. But I can assure you they do!
A Note from Umar
I avoid simply placing my computer science projects on GitHub. I personally believe that GitHub doesn't do as well of a job as showcasing the process of constructing a computer science project as a portfolio would. Therefore, I aim to display all my personal and internship projects on this site, showing not only my code but also my thought process in constructing the program.







