Welcome to Randi, the All-in-one movie chatbot
On this page, I will go over the functions I personally developed and worked on, but for more information on the code and function descriptions, feel free to check it out in my github repository for the project at: https://github.com/umarpatel23/Movie_Chatbot.git
We are given a long list of movie titles and their genre which can help us identify key elements in the user queries.
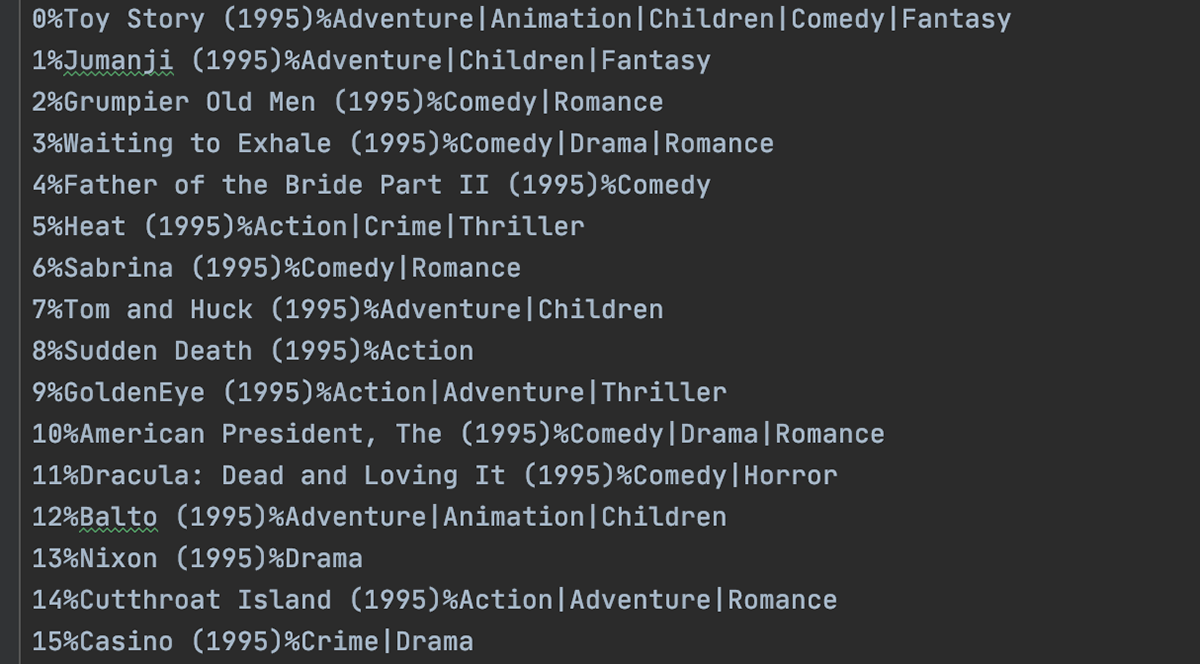
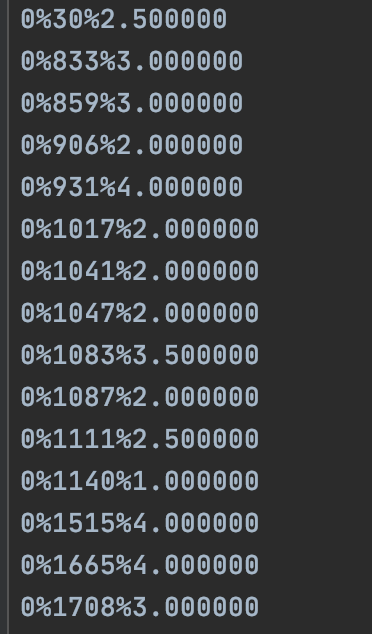
We also have a series of ratings given to each movie (each movie is identified by a specific index (i.e. first movie is 0, second movie is 1, etc.)), and the ratings are on a scale from 0 to 5, with 0 being the lowest score and 5 being the highest.
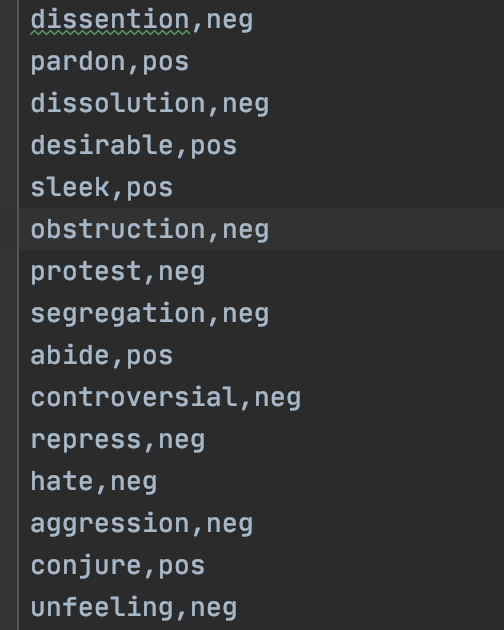
It is also important to develop a large and thorough list of varying sentiment words so that you are able to implement an extract sentiment mechanism from the user's query.
Key Functions and Implementations
Extract_Titles
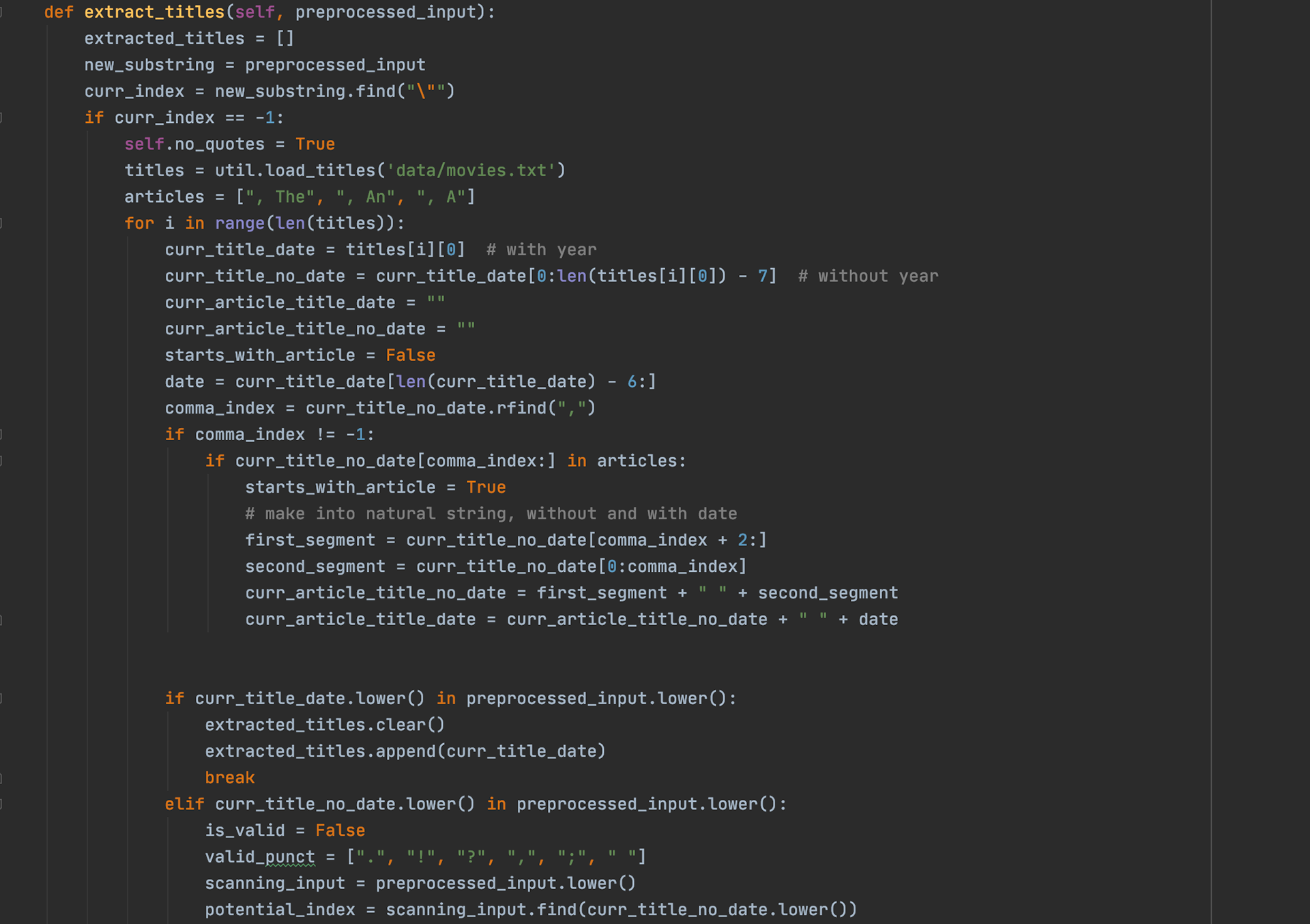
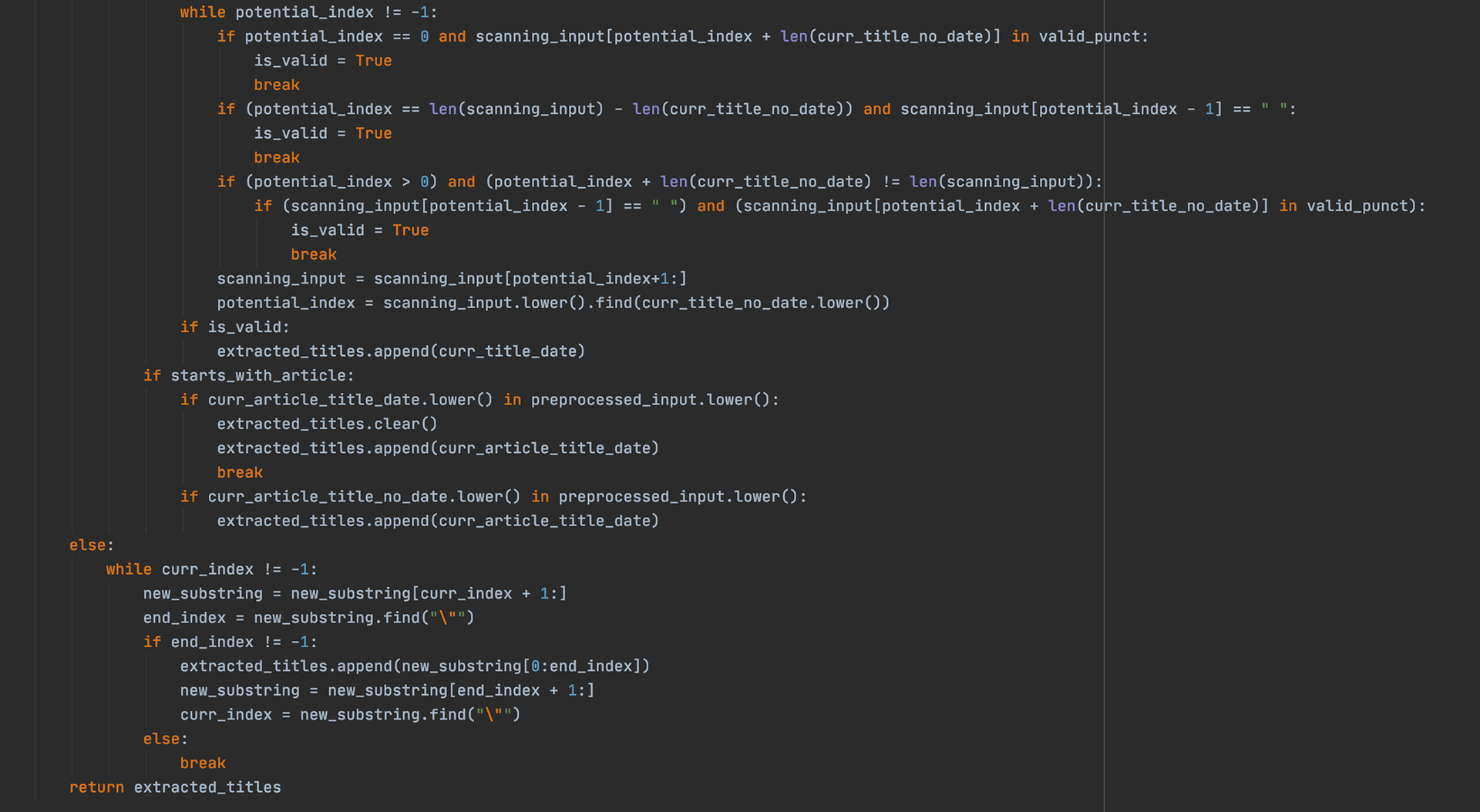
the above extract_titles function does simply that: extract the titles from the query. Users input statements such as "I liked 'Harry Potter'" or "i thought 'Beauty and the Beast' was great". The algorithm searches for quotation marks in the query which would indicate a movie title for it to search for. However, if the user did not use quotes, then the .find call early on in the function will return a -1 when searching for a "\"" character, and then the program will have to manually check through all of the movies in the database to see if any are contained in the User's input. If the quotes are present, then the process becomes much easier and the program simply extracts the string within the quotes.
Find_Movies_By_title
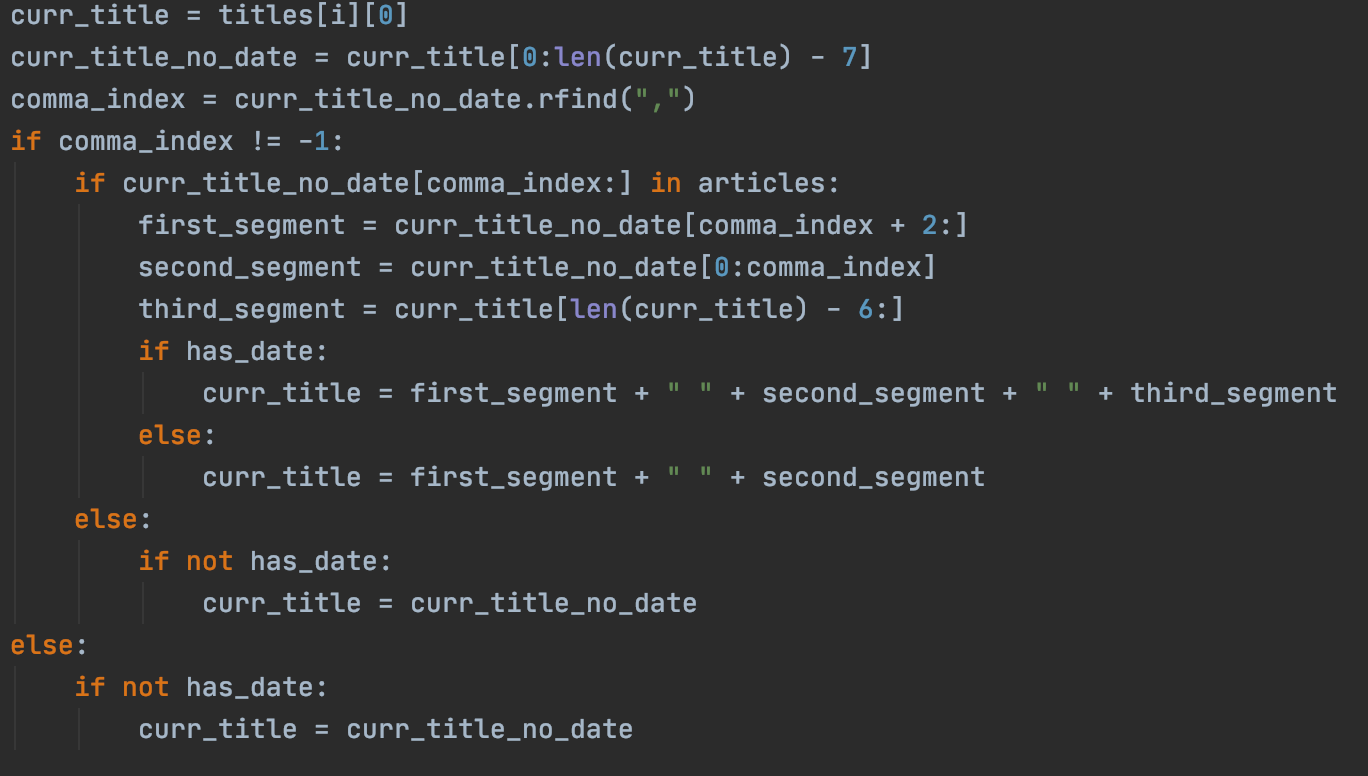
Now that we have extracted the titles from the User's query, we must 1) ensure that they entered a valid Movie title and 2) create a list of all the various possibilities for the movie titles if there is some ambiguity.
What this segment of code does is checks whether or not the user entered a specific year or not and then converts the current title in the list of all movies into the corresponding format before checking to see if the title matches.
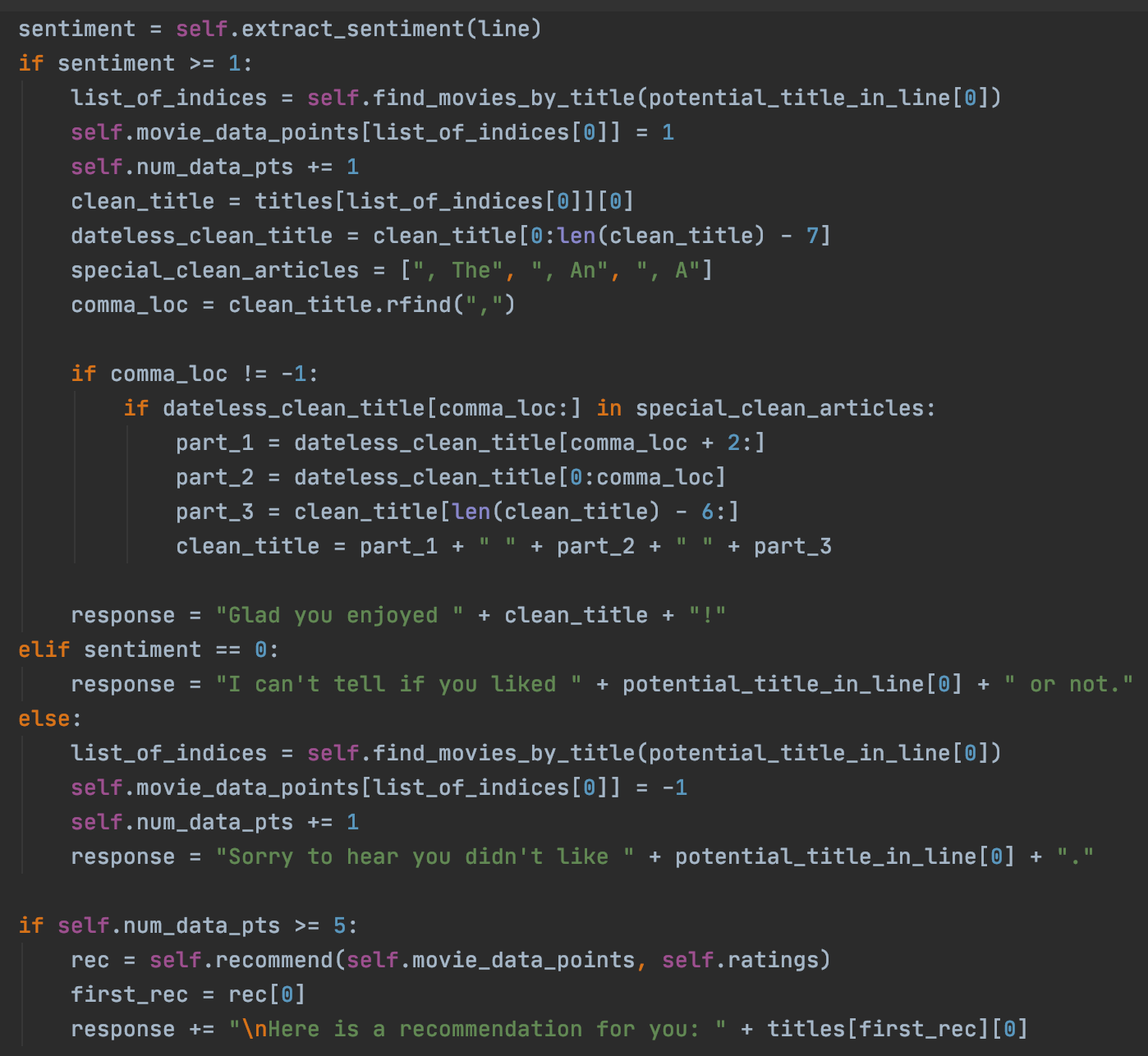
One tricky issue that arises is that in the movie database, those that start with an article (i.e., The, An, or A), have said article moved to the end of the title, separated by a comma. Therefore, the above code segment also has to adjust for this and adjust the segments so that we can compare the User title and database one accordingly.

Another tricky issue we must account for is that we do not want all the possible titles from the database which contain the user's movie query. FOr instance, if the user entered the 2017 horror movie "it", the string "it" could also be found in the string "Gone with the Wind," but it is almost certain the User did not mean the latter. Therefore, we want to ensure we don't capture examples like those. But we do want to capture titles such as "It Chapter two." This code segment does this processing for us to capture just the right titles.
Find_movies_closest_to_title
Using the NLP mechanism for closest edit distance, this function handles any misspellings of words in the query, and does so if no matches can be found in the previous function. This function only matches titles with an min edit distance of 3 or less so as to not start capturing undesired titles.
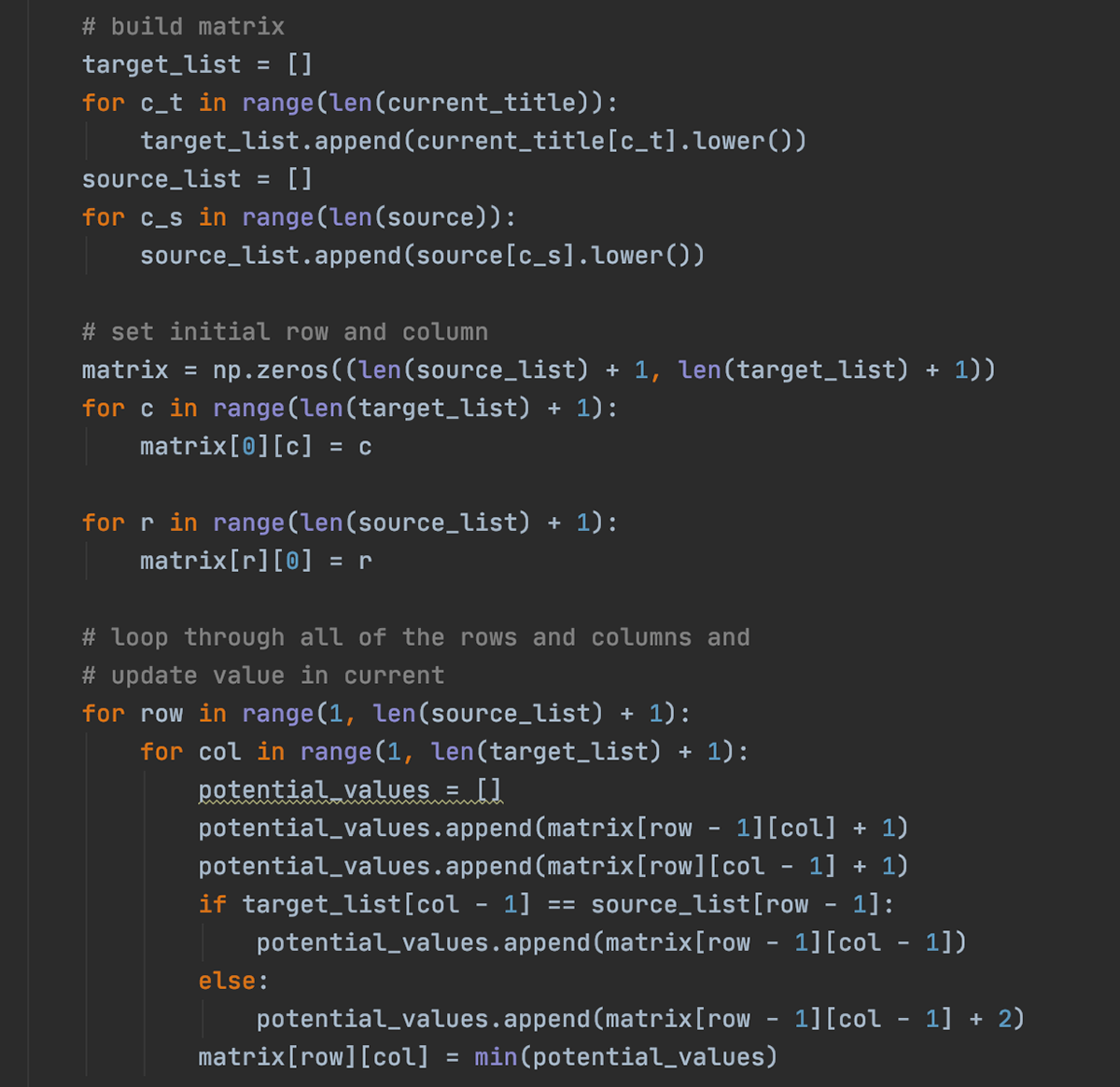
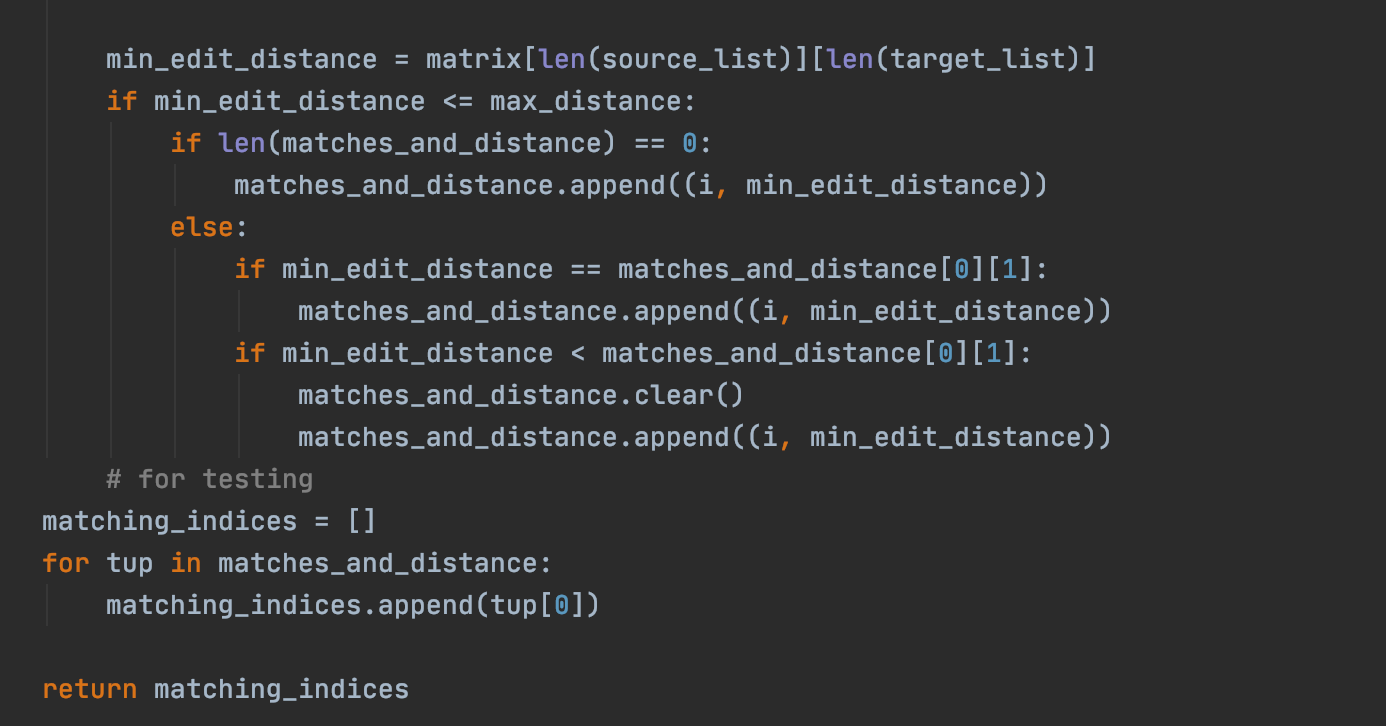
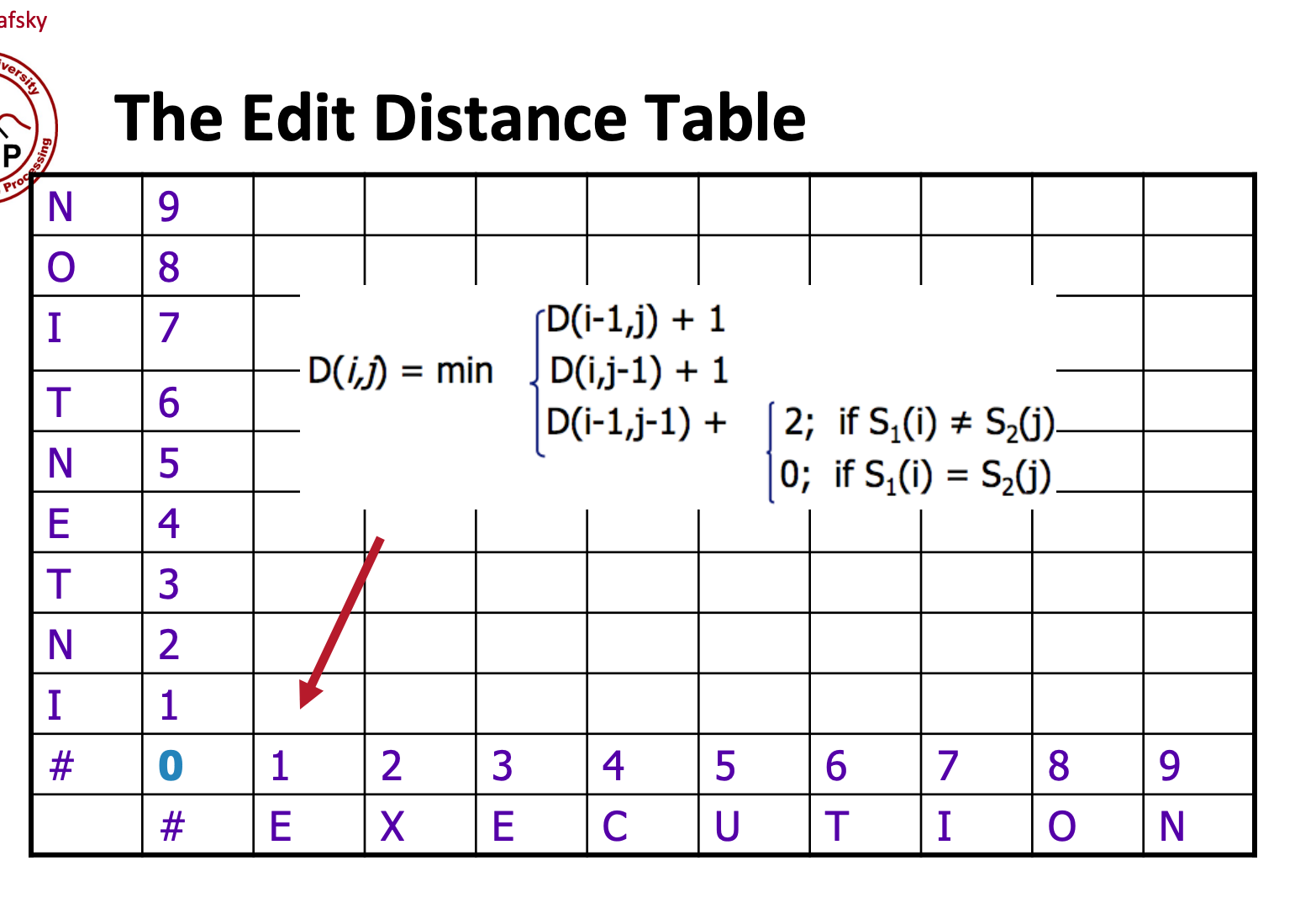
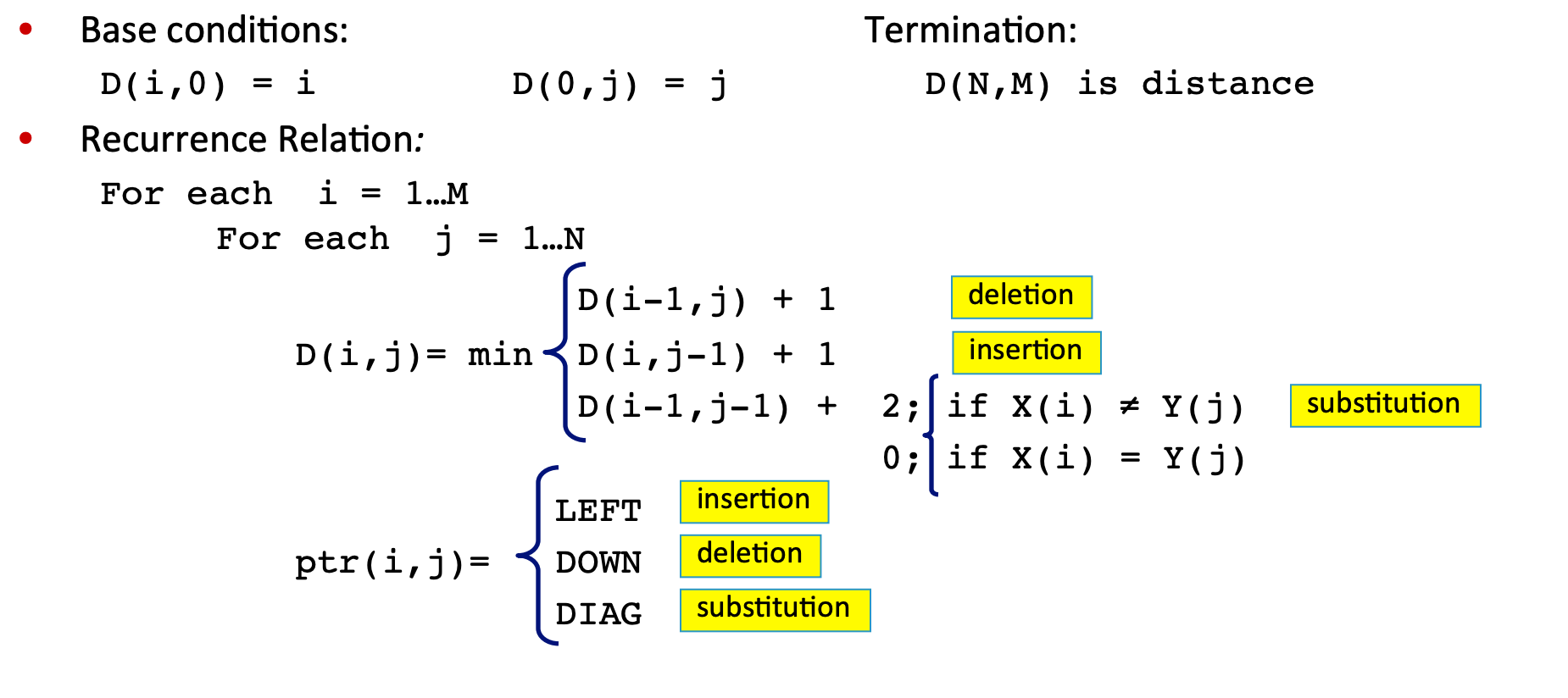
the algorithm for the min edit distance can be best represented through a table representing the insertions and deletions it will take to get from one word to another (hence, the Edit distance).
Process
The main function that controls the flow of the chatbot is "process", and alongside the other functions I have worked on outlined earlier on this page as well as other functions made by my group members outlined in the github, this function is the heart and soul of the chatbot.
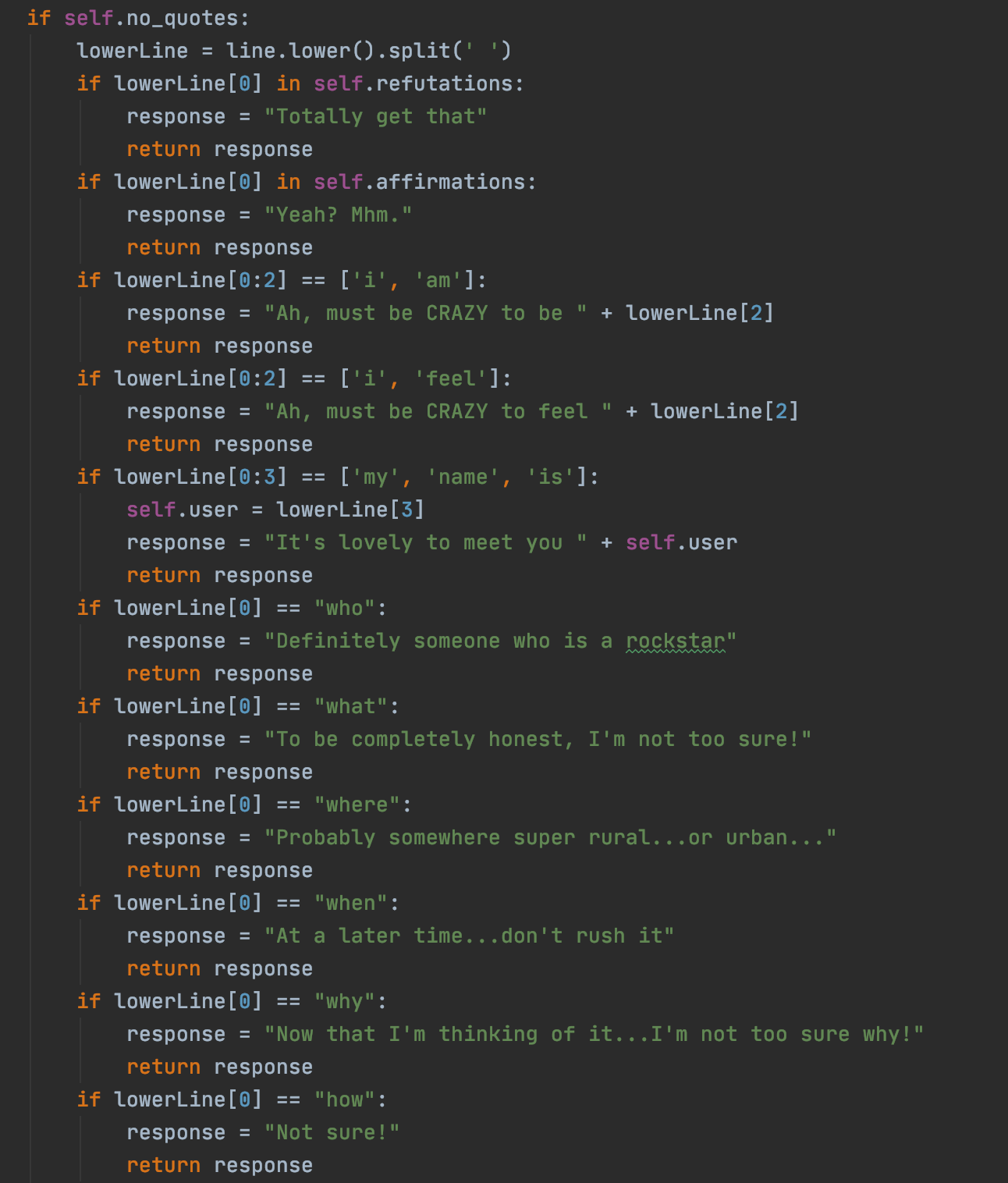
One of the first aspects in Process I had to account for are edge case queries, or user inputs that have nothing to do with movies and preferences. To account for this, we extracted the first few words from the input and if they matched any of the edge case scenarios, we created a generic but non-awkward response to allow for some flexibility and natural inclination to our chatbot. This prevents awkward responses that don't facilitate the continuation of conversation.
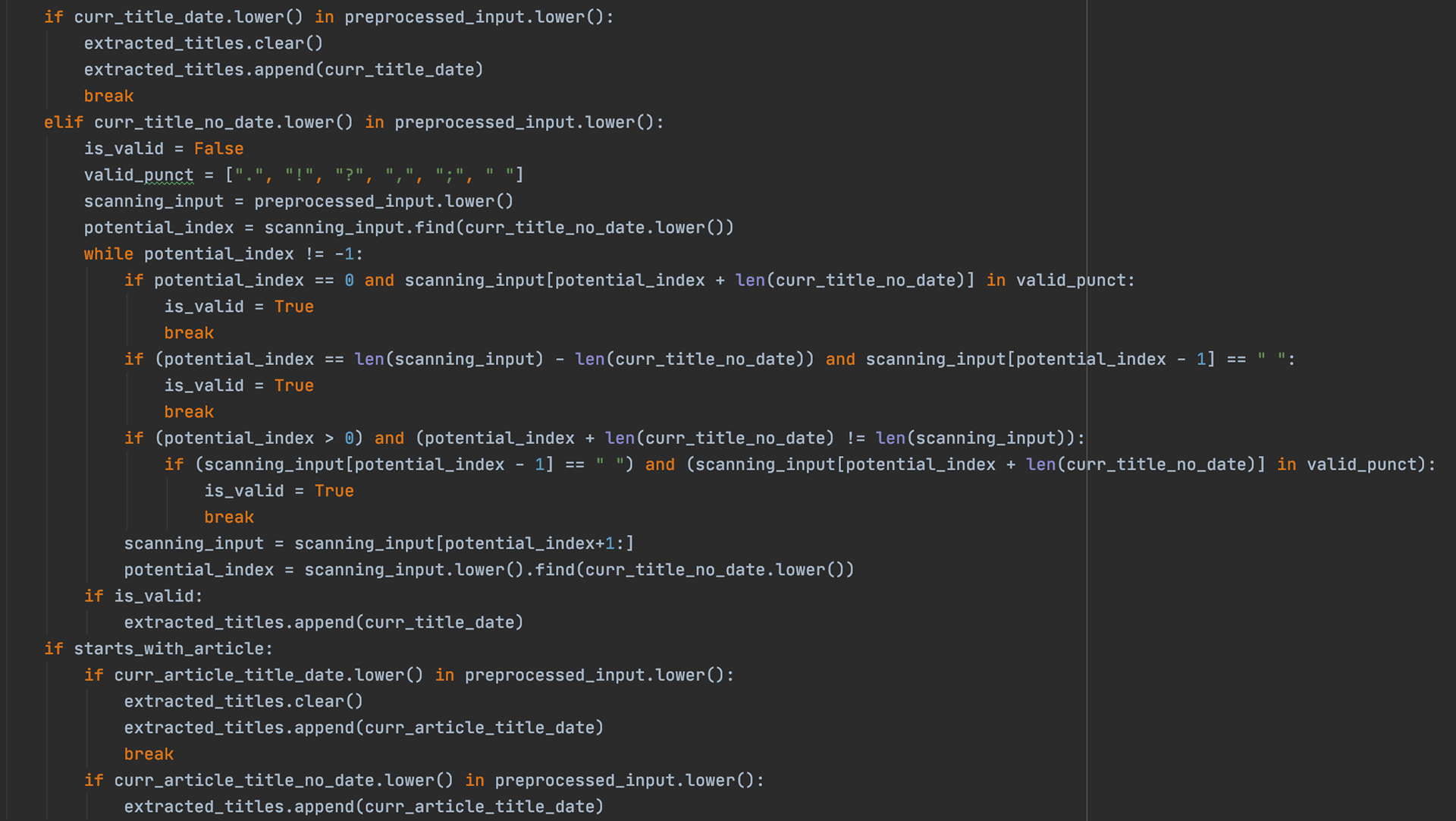
We must also account for the case where a user does not surround movie titles with quotation mark. In that case, we search the input for any potential movie titles and clarify if they meant any of them. To do this, we set the is_clarifying flag to true so that when the user inputs their next response, the process function knows it is a clarification of the last response, and not a new one. A separate code segment for clarifying responses is included and for more information on that part, please see the github page for this project.
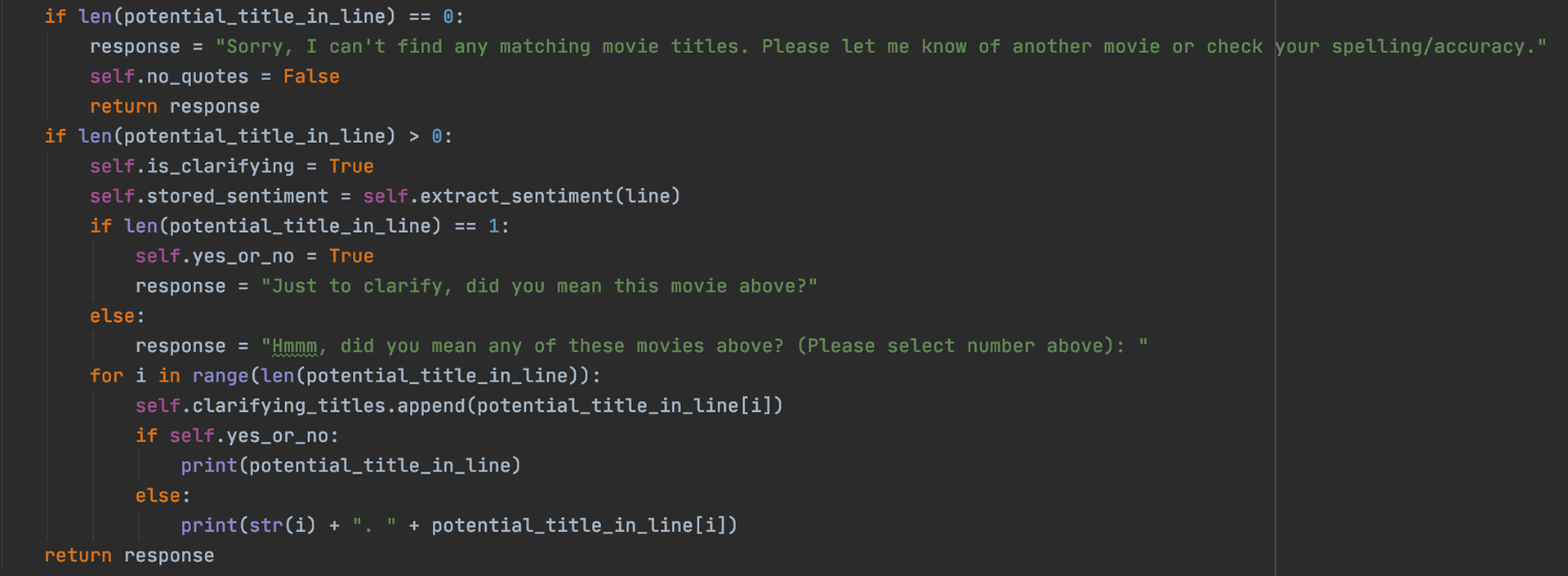
When there is more than one title with the same name as the one the User Inputed, we want to simplify our search to one, and so we set the Is_clarifying flag to true, process the input data so that we get all of the potential titles in the clarifying_titles data structure, and then return our clarifying response.
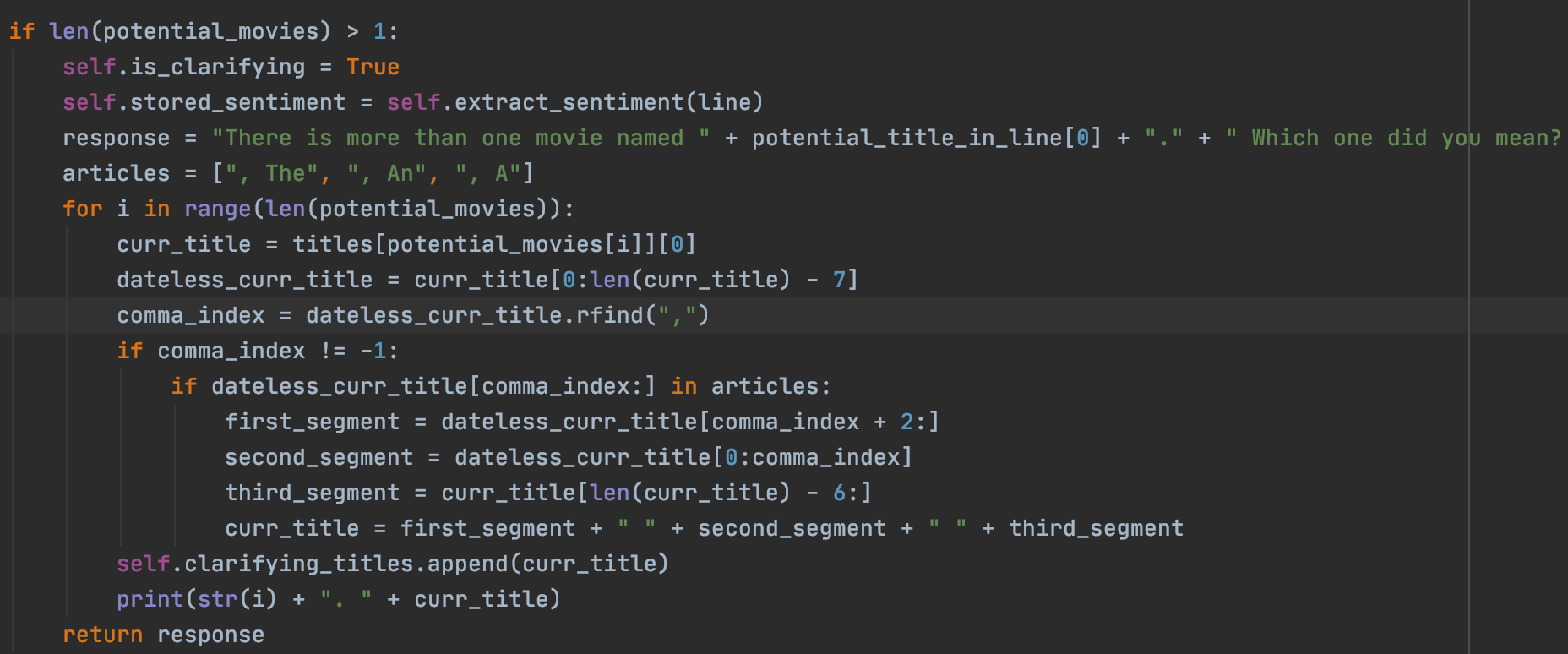
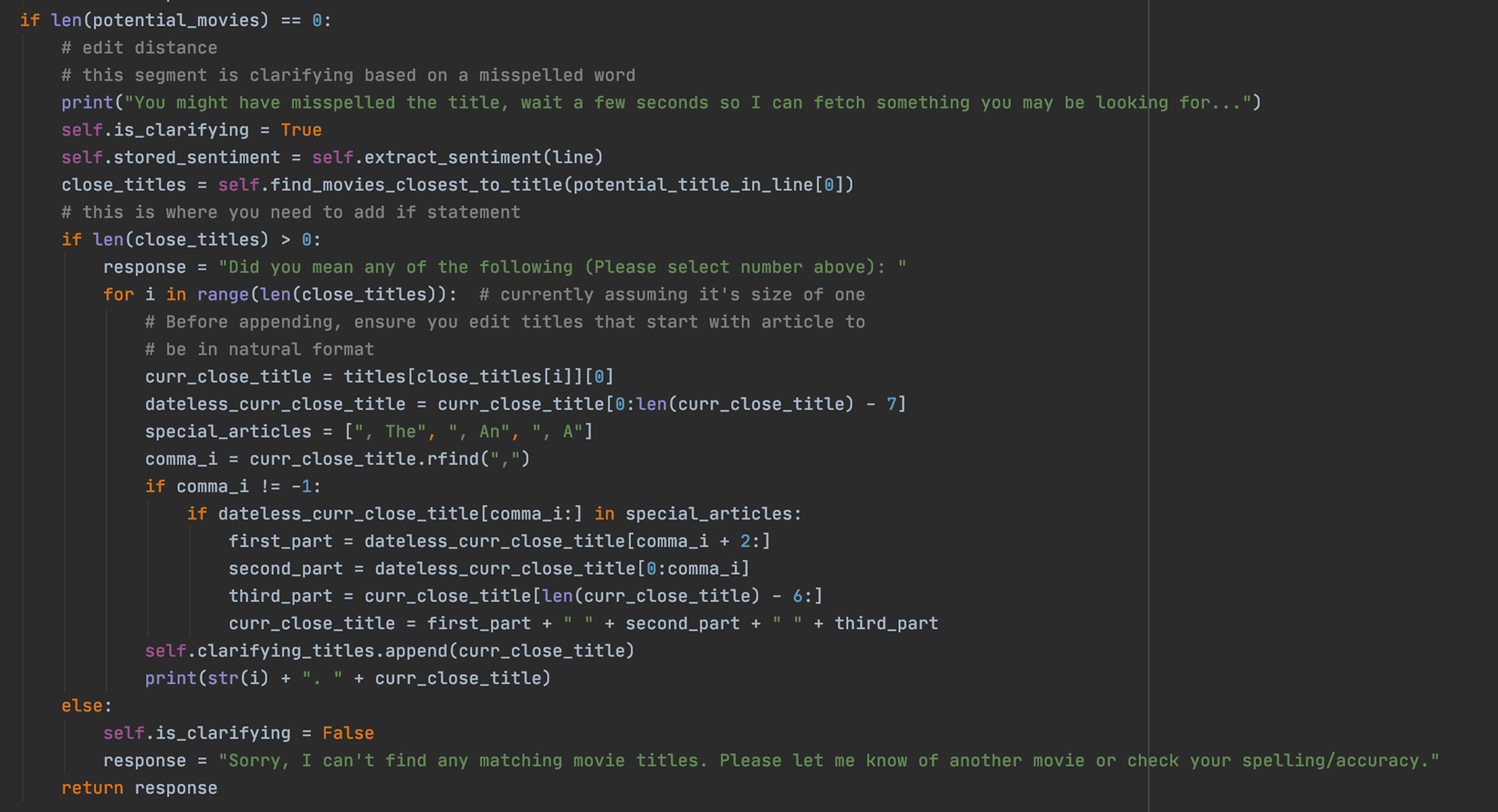
Using our edit distance function from above, if we see that there are no matches, we can check to see if there were misspellings using the find_movies_closest_to_title function, and clarify if any of those possibilities were what the user meant. Again, we set the Is_clarifying tag to True so that the clarifying code segment runs.
The last task to conduct in process is to get the sentiment of whatever movie the user inputed and to record that data in our matrix, and update the number of datapoints we have. Once we have 5 datapoints, we could then use User-User collaborative filtering to recommend new movies to the user.
A walkthrough of the concept of user-user collaborative filtering we used for our chatbot can be found at http://web.stanford.edu/class/cs124/lec/collaborativefiltering21.pdf.
As mentioned above, the functions and implementations of the chatbot that I mentioned on this Portfolio page are the ones I implemented. There are a few function which my group members worked on, and more information on those functions can be found on the github page linked above.
A Note From Umar
I avoid simply placing my computer science projects on GitHub. I personally believe that GitHub doesn't do as well of a job as showcasing the process of constructing a computer science project as a portfolio would. Therefore, I aim to display all my personal and internship projects on this site, showing not only my code but also my thought process in constructing the program.