This project involves using the NLTK library for natural language processing training as well as machine learning methods such as Naive Bayes in order to construct a simple sentiment analysis program that can determine whether a given Input (long or short) has an overall positive or negative sentiment. I built the program to display its output as if it were receiving reviews for a movie, but the program is easily adaptable to simply check whether the user input has a positive or negative sentiment.
Step 1: acquiring and organizing a corpus + Training
The first step involves getting a large amount of sample sentences or "reviews" with known sentiments to "train" the algorithm on. Although we want to make this program a general sentiment classifier, the NLTK has a great corpus of movie reviews which will work just as well as general statements or sentiments. Here, we load that data in to pos_movie_review_files and Neg_movie_review_files.
Some more processing to get all the individual words from the positive reviews corpus into the pos_words list, and the same for the negative reviews corpus.
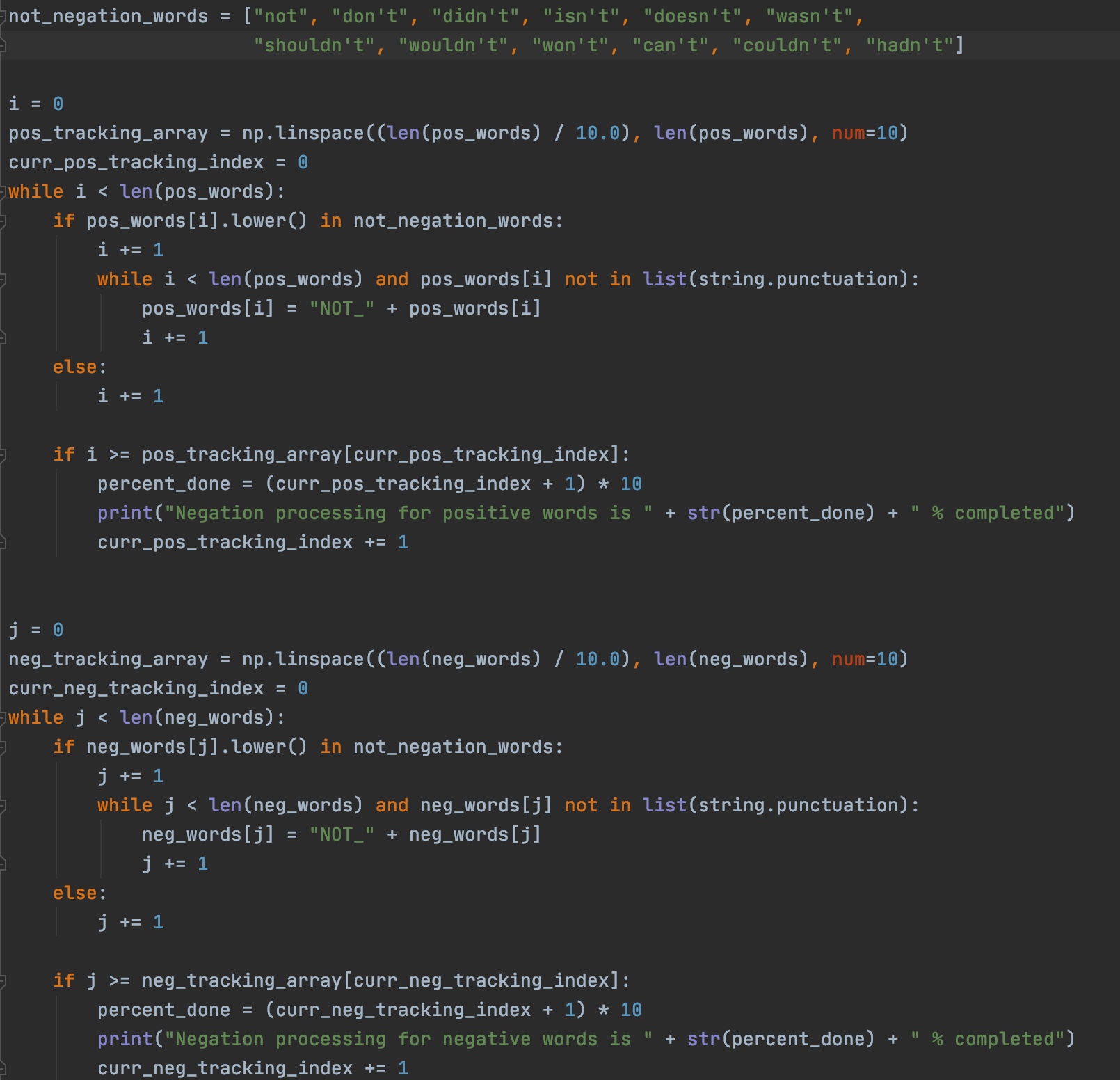
It's important to note that it is not always the case that a positive word signifies a positive sentiment. The main case where this is not true is when a negation word comes right before a word. We gathered a list of possible negation words which is shown at the top of the code snippet to the left, but of course one can add more depending on the corpus. For all words with one of these negation words, we add a prefix "NOT_" to them so that we know to change the sentiment of that word from positive to negative, or vice versa.
Of course, there are some common words or punctuations that do not contribute to the overall sentiment of the statement. The nltk library has a list of stop words and the string library has a list of punctuation marks. We create a combined list of those as well as lists of the top positive and negative words.
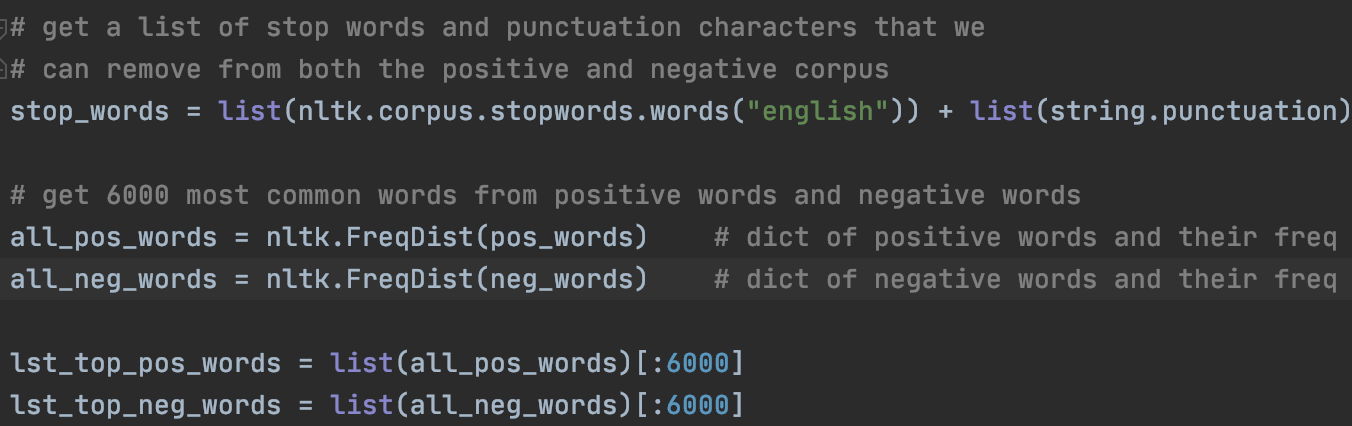
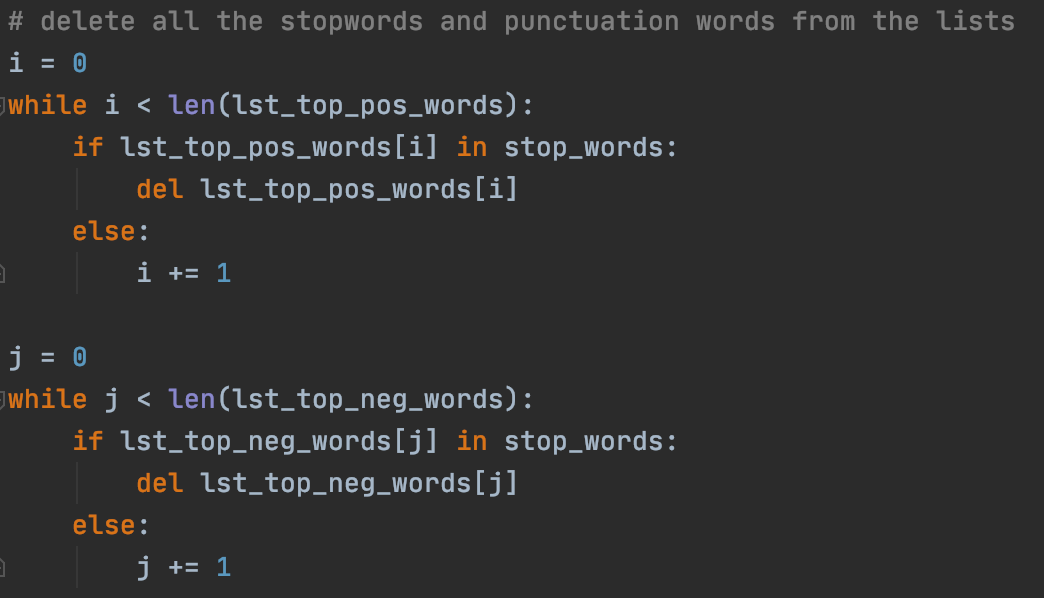
Using the list of stop words and punctuations, we can delete all stop words and punctuations from the top words in each class to get true sentiment words for each.
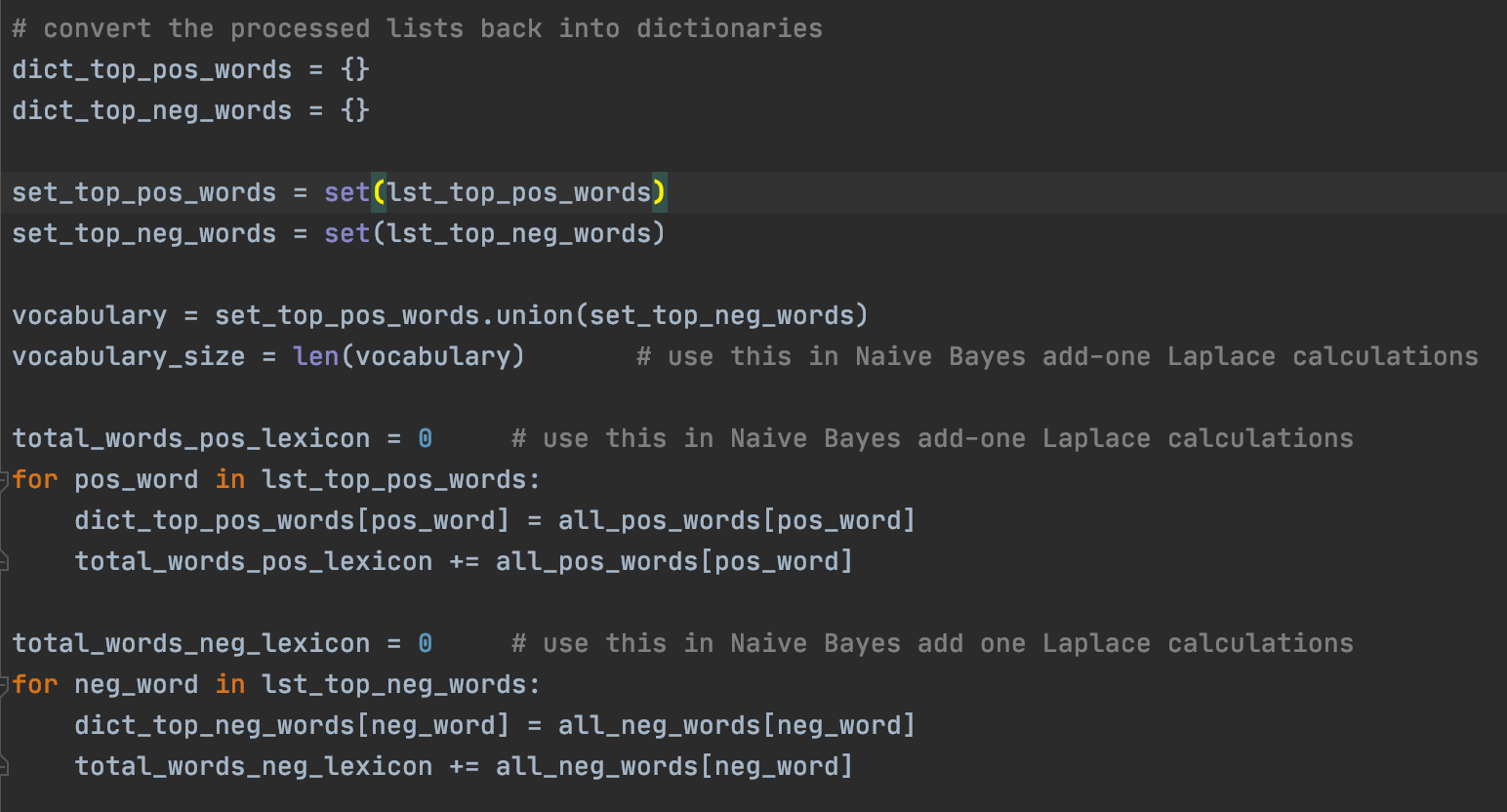
In order to use a Naive Bayes approach for classification, we must first get a vocabulary of words/tokens. To do this, we convert the list of top positive words and list of top negative words into sets and then get the union of the two. then, we get the frequency of each of the words and place them in their respective dictionary.
Step 2: Key NLP Functions
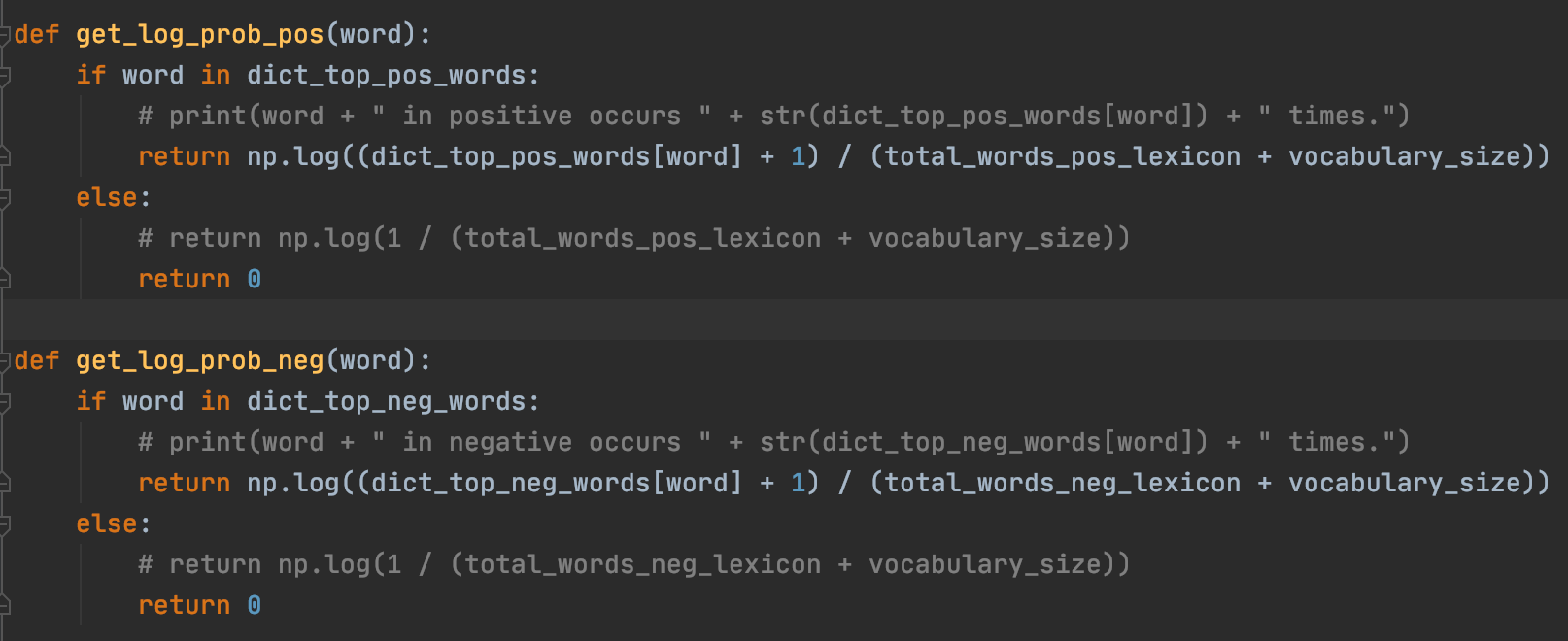
We use log probabilities so that we can add the "log-Probabilities" of each of the words. This is a key implementation to avoid underflow errors with small probabilities and multiplication.
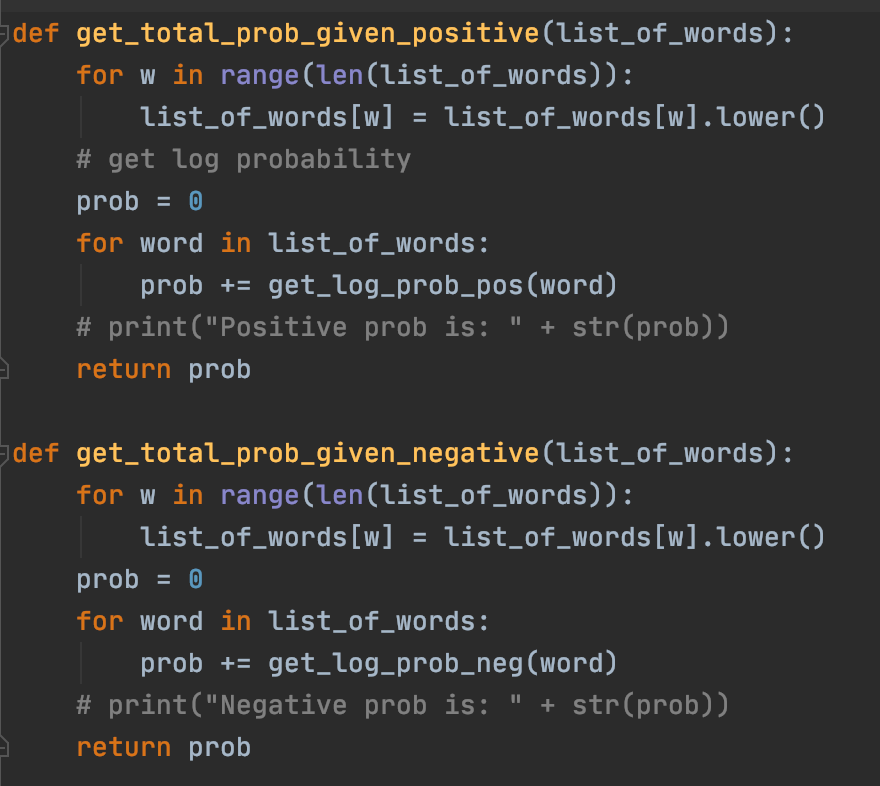
The following two functions simply use get_log_prob_pos and get_log_prob_neg to calculate the probability that an input (passed into the function as a list of all the words for that input) has a positive sentiment or a negative input. of course, the one that is the sentiment that will be returned to the user.
Program in Action
Affirmative positive or Affirmative Negative

Ambiguous

Improvements

longer, more strung out and complex inputs seem to confuse the naive bayes algorithm. Perhaps logistic regression or more training corpuses would improve the efficacy of this program.
A Note From Umar
I avoid simply placing my computer science projects on GitHub. I personally believe that GitHub doesn't do as well of a job as showcasing the process of constructing a computer science project as a portfolio would. Therefore, I aim to display all my personal and internship projects on this site, showing not only my code but also my thought process in constructing the program.